O Brasil foi o berço de uma das distribuições de Linux mais relevantes fora do eixo Estados Unidos–Europa, o Conectiva Linux, criado em 1995 e que quase colocou o país na rota de uma alternativa local e aberta ao Windows, da Microsoft. Desenvolvido em Curitiba, no Paraná, o projeto teve papel central na difusão do software livre no Brasil e na América Latina, em um momento em que o acesso à informática ainda era limitado e fortemente dependente de soluções proprietárias.
Fundada em 28 de agosto de 1995, a Conectiva surgiu a partir de um grupo liderado por Arnaldo Carvalho de Melo, um dos principais desenvolvedores do kernel Linux no mundo. Um de seus primeiros marcos foi a tradução do Slackware, distribuição pioneira do sistema, para o português, reduzindo barreiras técnicas e linguísticas para usuários brasileiros.
Ao adaptar o Linux à realidade local, a Conectiva ofereceu suporte completo em português e ferramentas gráficas que simplificavam a instalação e a configuração do sistema. Em um cenário dominado pelo Windows, esses recursos tornaram a distribuição atraente para iniciantes, pequenas empresas e instituições de ensino, além de estimular a formação de comunidades técnicas em torno do código aberto.
O modelo de negócios da empresa ia além do sistema operacional. A Conectiva passou a oferecer consultoria, treinamentos, desenvolvimento de software e contratos de manutenção, criando um ecossistema profissional em torno do Linux. Na virada dos anos 2000, a distribuição ganhou espaço tanto entre usuários domésticos quanto no ambiente corporativo, apoiada pela combinação de usabilidade e estabilidade.
A venda para a Mandrake e o fim da marca
A trajetória do Conectiva começou a mudar em meados dos anos 2000. Em 2005, a empresa foi adquirida pela francesa Mandrake Linux por US$ 2,23 milhões, valor que equivalia a cerca de R$ 6 milhões na época. A operação deu origem à Mandriva S.A. e à distribuição Mandriva Linux, que incorporou tecnologias e equipes do projeto brasileiro.
Embora a fusão tenha ampliado o alcance internacional do software, ela também marcou o fim da marca Conectiva como distribuição independente. Com o avanço de concorrentes globais e mudanças no mercado de sistemas operacionais, a Mandriva perdeu relevância ao longo dos anos, e a versão brasileira acabou descontinuada.
Mesmo sem ter disputado diretamente o mercado com o Windows, o legado do Conectiva permanece. A iniciativa ajudou a formar profissionais, fortaleceu comunidades de software livre e contribuiu para a discussão sobre autonomia tecnológica no Brasil, influência que ainda se reflete em projetos de código aberto na região.
Publicado em Portal Exame
Os líderes empresariais entram em 2026 diante de uma nova realidade: agentes de IA automatizam fluxos de trabalho inteiros, plataformas de nuvem setoriais se tornam determinantes para a vantagem competitiva e ameaças quânticas deixam de ser teoria para entrar no planejamento estratégico. Essas tecnologias estão remodelando os alicerces da estratégia corporativa e aumentando a pressão sobre qualquer organização que queira se manter relevante em um mercado saturado. O próximo ano deve recompensar quem sair da especulação e avançar para a criação de valor prático.
A seguir, apresento as oito tecnologias que, na minha visão, vão definir 2026 — com foco naquelas que devem superar o hype e gerar crescimento real, diferenciando líderes de retardatários ao longo do ano:
1 – Plataformas Agênticas
Esqueça os chatbots: os agentes são o próximo estágio da evolução da IA corporativa, e 2026 será o ano de sua expansão. Em vez de simplesmente responder perguntas ou gerar conteúdo, esses agentes executam processos complexos de múltiplas etapas e interagem com serviços de terceiros. Imagine colegas de trabalho virtuais, assistentes sempre ativos que monitoram e ajustam processos em tempo real, e fluxos de trabalho automatizados de ponta a ponta, exigindo o mínimo de intervenção humana. Essas plataformas permitem que empresas implementem agentes em larga escala, usando interfaces low-code/no-code e mantendo a governança, a ética e a conformidade necessárias para operações autônomas.
2 – Copilotos de IA Generativa
A IA generativa aplicada ao conhecimento está evoluindo rapidamente do estágio de pilotos corporativos para adoção operacional. Ela já transforma fluxos de trabalho ao gerar código para desenvolvedores, redigir contratos para áreas jurídicas e criar cronogramas e planos de ação para gerentes de projetos. Não se trata de substituir pessoas, mas de ampliar suas capacidades. A IDC prevê que, até 2026, assistentes virtuais de IA estarão integrados em 80% dos aplicativos corporativos, ajudando profissionais a trabalhar de forma mais inteligente e eficiente.
3 – Plataformas de Nuvem Especializadas por Setor
As empresas estão indo além das plataformas de nuvem genéricas e adotando cada vez mais as chamadas Plataformas de Nuvem por Setor (ICPs), que oferecem soluções verticais combinando infraestrutura, aplicativos e dados. Provedores como Google e Microsoft já oferecem plataformas específicas para áreas como saúde, finanças e ciências, com modelos de dados pré-construídos e configurações de conformidade. A Gartner prevê que, até o fim de 2026, 70% das empresas usarão ICPs, um salto expressivo em relação aos menos de 15% em 2023.
4 – Computação Quântica
A relevância da computação quântica para os negócios em 2026 tem dois eixos principais.
Primeiro: as oportunidades transformadoras em setores como finanças, logística e pesquisa farmacêutica, graças à capacidade de resolver cálculos extremamente complexos que seriam inviáveis para computadores tradicionais.
Segundo: a necessidade de preparação. A computação quântica representa uma ameaça real aos padrões de criptografia usados para proteger dados e comunicações. Por isso, 2026 marca o prazo final para que empresas iniciem sua migração para modelos de criptografia resistentes à computação quântica — uma prioridade estratégica para o ano.
5 – Edge de Confiança Zero
Essa tendência surge tanto pela explosão de dispositivos IoT quanto pelo avanço do trabalho remoto e híbrido. O conceito de “edge de confiança zero” (ZTE, na sigla em inglês) refere-se à segurança integrada diretamente nos dispositivos de borda — de máquinas industriais a smartphones e plataformas em nuvem — garantindo gestão consistente de acessos e identidades. Com 72% das organizações adotando ou planejando adotar frameworks de confiança zero, o foco em 2026 será a verificação de identidade e permissões no próprio ponto de criação e acesso dos dados, oferecendo proteção em tempo real e reduzindo riscos de ataques “man-in-the-middle”.
6 – Realidade Estendida (XR)
A realidade estendida — que inclui VR e AR — vem ganhando força corporativa nos últimos anos e deve se consolidar em 2026. Com headsets cada vez menores, leves e potentes, além do lançamento de novos óculos inteligentes, o mercado de XR deve atingir US$ 380 bilhões até 2036. Entre as aplicações mais relevantes estão: treinamento imersivo, assistência remota de especialistas, acesso a informações no trabalho sem uso das mãos e alertas em tempo real em ambientes de risco.
7 – Tecnologia Sustentável
Em 2025, integrar sustentabilidade à estratégia tecnológica deixou de ser opcional para muitas empresas, em razão da Diretiva Europeia de Relatórios de Sustentabilidade Corporativa. A partir de janeiro, grandes corporações passaram a ser obrigadas a apresentar relatórios detalhados sobre impacto ambiental e ações de mitigação. Em resposta, empresas têm adotado princípios de engenharia de software verde, reduzido emissões em infraestrutura digital e usado IA para monitorar suas operações. Em 2026, a estratégia passa a ser “sustentável por natureza”, tornando a sustentabilidade parte estrutural do negócio.
8 – Gêmeos Digitais
Os gêmeos digitais estão evoluindo de simulações isoladas para modelos completos de processos, instalações — como fábricas — ou até organizações inteiras. Integrando dados de múltiplas fontes, sensores em tempo real e modelos de IA, as empresas estão migrando de análises reativas para capacidades preditivas. Isso reduz tempo de desenvolvimento, diminui interrupções por falhas e aprimora a eficiência operacional. Em 2026, os gêmeos digitais deixam de ser ferramentas de engenharia e passam a atuar como centros neurais das operações, permitindo testar decisões críticas sem risco ou custo no mundo físico.
Publicado em: Forbes
Durante anos, a liderança no mundo dos negócios foi guiada por experiência, intuição e habilidade de comunicação. Essas qualidades continuam sendo importantes — mas hoje, não são suficientes.
Com o avanço da Inteligência Artificial (IA), a realidade mudou. Decisões estratégicas estão cada vez mais embasadas em dados e automatizadas por ferramentas que analisam padrões, identificam oportunidades e antecipam riscos com precisão quase instantânea.
E o mais importante: essa transformação já está acontecendo. Os profissionais que lideram esse processo têm um diferencial competitivo real e imediato.

Muitos ainda associam a IA a algo distante, sofisticado demais ou exclusivo da área de tecnologia. A verdade é que a Inteligência Artificial já está presente no dia a dia das empresas e moldando a forma como os negócios são pensados, geridos e escalados.
41% das empresas brasileiras já utilizam IA em pelo menos uma área do negócio; (IBM Global AI Adoption Index)
65% dos executivos só contratam quem domina IA; (Work Trend Index Annual Report 2024)
Empresas que integram IA aos processos decisórios aumentaram a produtividade em até 40%. (McKinsey & Company)
A mensagem é clara: não se trata mais de acompanhar uma tendência, mas de liderar uma transição que já está em curso.
A transformação digital já não é novidade. O que está em jogo agora é a transformação do perfil de liderança.
O mercado exige líderes que compreendam o impacto da tecnologia nos resultados e saibam utilizá-la de forma estratégica. Isso não significa que todo gestor precise ser um especialista técnico ou programador, mas é fundamental que domine o uso prático de ferramentas que estão mudando a lógica dos negócios.
Toma decisões baseadas em análise de dados em tempo real;
Aplica IA para otimizar marketing, finanças, operações e atendimento ao cliente;
Automatiza processos repetitivos e foca no que mais importa: inovação, estratégia e crescimento;
Conduz equipes mais preparadas, adaptáveis e produtivas.
Enquanto muitos veem a IA com receio ou hesitação, os líderes mais preparados estão aproveitando o momento para se destacar.
É comum ouvir que a IA vai “tomar empregos”. Na prática, a IA não substitui profissionais preparados, ela amplia suas capacidades. O que muda é o perfil do profissional valorizado.
Líderes que sabem como aplicar IA no contexto de negócios estão conquistando:
Promoções mais rápidas;
Projetos estratégicos e de alto impacto;
Maior capacidade de inovar e gerar valor;
Reconhecimento como referência dentro de suas áreas de atuação.
Quem aprende a usar a IA como aliada, deixa de apenas acompanhar tendências e passa a definir os rumos da organização.
O iCEV está com inscrições abertas para a Pós-Graduação em Ferramentas de Inteligência Artificial para Negócios, uma formação criada para preparar profissionais que desejam mais do que apenas acompanhar o mercado — querem liderar a transformação.
Formação prática, com foco em ferramentas e soluções reais de IA aplicadas a diferentes áreas do negócio;
Não é preciso saber programar — o curso é voltado para profissionais de gestão, estratégia, marketing, finanças, RH, entre outros;
Aulas com especialistas atuantes no mercado, conectados com as últimas tecnologias e práticas empresariais;
Um ambiente voltado para desenvolvimento de competências, análise crítica e aplicação imediata.
É um curso feito para quem quer aprender a usar a IA de forma estratégica, pensando sempre em impacto, performance e inovação.
Não espere mais. O próximo passo para liderar com inteligência começa agora.
Inscreva-se na Pós em Ferramentas de Inteligência Artificial para Negócios do iCEV: https://cev.bz/icevpos
Vagas limitadas!
No iCEV, o futuro não é algo que a gente espera. É algo que a gente faz acontecer. E a conquista do selo Ready Tier da Red Hat Academy é a prova disso. Um reconhecimento internacional que destaca instituições com alto desempenho e dedicação na formação em tecnologias da Red Hat, uma das maiores potências do mundo em soluções open source.

Todos os nossos alunos do curso de Engenharia de Software já têm acesso gratuito à plataforma da Red Hat Academy, com cursos, laboratórios e conteúdos que são os mesmos usados por gigantes da tecnologia. E agora, com o selo Ready, ganhamos acesso a treinamentos avançados, materiais exclusivos, suporte direto da Red Hat e descontos especiais em certificações internacionais.
E quem vai representar essa conquista junto aos colegas é o aluno embaixador da Red Hat Academy no iCEV, Felipe Duan da Silva Sousa, 3º período, turma Ada. Ele ganhará uma prova de certificação gratuita.
Segundo o professor Luciani Vieira, responsável por conduzir essa parceria, a conquista é resultado de um trabalho feito em equipe e pensado no aluno.
“O reconhecimento da Red Hat é uma validação do nosso compromisso com a qualidade da formação dos nossos alunos. Trabalhamos para garantir que eles tenham acesso às tecnologias mais modernas, com acompanhamento próximo dos professores e integração real com o mercado”, afirma.
A participação dos alunos é guiada de forma estratégica. Cada módulo é liberado conforme o período em que o estudante está matriculado, sempre com o acompanhamento dos professores. Isso garante que todos tenham uma experiência de aprendizado coerente com sua etapa na graduação, com teoria, prática e certificações andando juntas.
Mais do que um curso, uma vantagem competitiva
Os alunos do iCEV têm nas mãos um diferencial poderoso: a chance de se certificar em tecnologias reconhecidas globalmente, como Linux, OpenShift, Ansible e muito mais. Isso tudo enquanto ainda estão na graduação.
E tem mais, nossos alunos também desfrutam de uma inserção mais ampla no mercado de trabalho, acesso direto às ferramentas utilizadas pelas grandes empresas, desenvolvimento de habilidades práticas e estratégicas, oportunidades de networking com profissionais renomados da área e participação em campanhas e eventos oficiais da Red Hat.
Aqui no iCEV formamos profissionais com visão, competência e protagonismo para liderar os avanços da inovação.
A inteligência artificial está marcando um momento definidor na história da tecnologia — e o ano de 2025 trará ainda mais surpresas.
Não é fácil fazer uma previsão do que esperar, mas é possível destacar tendências e desafios que definem o futuro imediato da IA para o próximo ano.
Entre eles, o desafio dos chamados “médico centauro” ou “professor centauro”, fundamental para quem está desenvolvendo inteligência artificial.

A explosão da ciência baseada em IA
A IA virou uma ferramenta fundamental para se enfrentar grandes desafios científicos. Áreas como saúde, astronomia e exploração espacial, neurociência ou mudanças climáticas, entre outras, vão se beneficiar ainda mais no futuro.
Seu desenvolvimento representa um avanço significativo na Biologia Molecular e na Medicina. Isso facilita a concepção de novos medicamentos e tratamentos. Em 2025, isso começará a acontecer — e com acesso gratuito ao AlphaFold para quem for desenvolver remédios e tratamentos.
Já a rede ClimateNet utiliza redes neurais artificiais para realizar análises espaciais e temporais precisas de grandes volumes de dados climáticos, essenciais para compreender e mitigar o aquecimento global.
A utilização do ClimateNet será essencial em 2025 para prever eventos climáticos extremos com maior precisão.
A justiça e a Medicina são considerados campos de alto risco. Neles é mais urgente do que em qualquer outra área estabelecer sistemas para que os humanos tenham sempre a decisão final.
Os especialistas em IA trabalham para garantir a confiança dos usuários, para que o sistema seja transparente, que proteja as pessoas e que os humanos estejam no centro das decisões.

Aqui entra em jogo o desafio do “doutor centauro”. Centauros são modelos híbridos de algoritmo que combinam análise formal de máquina e intuição humana.
Um “médico centauro + um sistema de IA” melhora as decisões que os humanos tomam por conta própria e que os sistemas de IA tomam por conta própria.
O médico sempre será quem aperta o botão final; e o juiz quem determina se uma sentença é justa.
A IA que tomará decisões no nosso lugar
Agentes autônomos de IA baseados em modelos de linguagem são a meta para 2025 de grandes empresas de tecnologia como OpenAI (ChatGPT), Meta (LLaMA), Google (Gemini) ou Anthropic (Claude).
Até agora, estes sistemas de IA fazem recomendações. Em 2025, no entanto, espera-se que eles tomem decisões por nós.
Os agentes de IA realizarão ações personalizadas e precisas em tarefas que não sejam de alto risco, sempre ajustadas às necessidades e preferências do usuário. Por exemplo: comprar uma passagem de ônibus, atualizar a agenda, recomendar uma compra específica e executá-la.
Eles também poderão responder nosso e-mail — tarefa que nos toma muito tempo diariamente.
Nessa linha, a OpenAI lançou o AgentGPT, e o Google lançou o Gemini 2.0. Essas plataformas podem ser usadas para o desenvolvimento de agentes autônomos de IA.
Por sua vez, a Anthropic propõe duas versões atualizadas de seu modelo de linguagem Claude: Haiku e Sonnet.
O uso do nosso computador pela IA
O programa Sonnet consegue usar um computador do mesmo jeito que uma pessoa. Isso significa que ele consegue mover o cursor, clicar em botões, digitar texto e navegar por telas.
Ele também permite funcionalidade para automatizar a área de trabalho. Ele permite que os usuários concedam a Claude acesso e controle sobre certos aspectos de seus computadores pessoais.
Esta capacidade apelidada de “uso do computador” poderá revolucionar a forma como automatizamos e gerimos as nossas tarefas diárias.
No comércio eletrônico, agentes autônomos de IA poderão fazer uma compra no lugar do usuário.
Eles prestarão assessoria na tomada de decisões de negócios, gerenciarão estoques automaticamente, trabalharão com fornecedores de todos os tipos, inclusive logísticos, para otimizar o processo de reabastecimento, atualizarão o status de envio até a geração de faturas, etc.
No setor educacional, eles poderão customizar os planos de estudos dos alunos. Eles identificarão áreas para melhoria e sugerirão recursos de aprendizagem apropriados.
Caminharemos em direção ao conceito de “professor centauro”, auxiliado por agentes de IA na educação.
O botão ‘aprovar’
A noção de agentes autônomos levanta questões profundas sobre o conceito de “autonomia humana e controle humano”.
O que significa realmente “autonomia”?
Esses agentes de IA criarão a necessidade de pré-aprovação. Quais decisões permitiremos que estas entidades tomem sem a nossa aprovação direta (sem controle humano)?
Enfrentamos um dilema crucial: saber quando é melhor ser “automático” na utilização de agentes autônomos de IA e quando é necessário tomar a decisão, ou seja, recorrer ao “controle humano” ou à “interação humano-IA”.
O conceito de pré-aprovação vai ganhar grande relevância na utilização de agentes autônomos de IA.
O pequeno ChatGPT no celular
2025 será o ano da expansão dos modelos de linguagem pequena e aberta (SLM).
São modelos de linguagem que futuramente poderão ser instalados num dispositivo móvel, permitindo controlar o nosso telefone por voz de uma forma muito mais pessoal e inteligente do que com assistentes como a Siri.
SLMs são compactos e mais eficientes, não requerem servidores massivos para serem usados. Estas são soluções de código aberto que podem ser treinadas para cenários específicos.
Eles podem respeitar mais a privacidade do usuário e são perfeitos para uso em computadores e celulares de baixo custo.
Eles têm potencial para adoção no nível empresarial. Isto será viável porque os SLMs terão um custo menor, mais transparência e, potencialmente, maior transparência e controle.
Os SLMs permitirão integrar aplicações de recomendações médicas, de educação, de tradução automática, de resumo de textos ou de correção ortográfica e gramatical instantânea. Tudo isso em pequenos dispositivos sem a necessidade de conexão com a internet.
Entre as suas importantes vantagens sociais, eles podem facilitar a utilização de modelos linguísticos na educação em áreas desfavorecidas.
E podem melhorar o acesso a diagnósticos e recomendações com modelos de SLM de saúde especializados em áreas com recursos limitados.
O seu desenvolvimento é essencial para apoiar comunidades com menos recursos.
E podem acelerar a presença do “professor ou médico centauro” em qualquer região do planeta.
Avanços na regulamentação europeia da IA
Em 13 de junho de 2024, foi aprovada a legislação europeia sobre IA, que entrará em vigor em dois anos. Ao longo de 2025, serão criadas normas e padrões de avaliação, incluindo padrões ISO e IEEE.
Em 2020, a Comissão Europeia havia publicado a primeira Lista de Avaliação para IA Confiável (ALTAI). Esta lista inclui sete requisitos: agência humana e supervisão, robustez técnica e segurança, governança e privacidade de dados, transparência, diversidade, não discriminação e equidade, bem-estar social e ambiental e responsabilidade. Essa lista constitui a base das futuras normas europeias.
Ter padrões de avaliação é fundamental para auditar sistemas de IA. Por exemplo: o que acontece se um veículo autônomo sofrer um acidente? Quem assume a responsabilidade? O quadro regulamentar abordará questões como estas.
Mecanismos de governança
Dario Amodei, CEO da Anthropic, em seu ensaio intitulado “Machines of Loving Grace” (“Máquinas de graça amorosa”, em tradução livre), de outubro de 2024, expõe a visão das grandes empresas de tecnologia: “Acho que é essencial ter uma visão verdadeiramente inspiradora do futuro, e não apenas um plano para apagar incêndios.”
Existem pontos de vista contrastantes de outros pensadores mais críticos. Por exemplo, aquele representado por Yuval Noah Harari e discutido em seu livro Nexus: Uma Breve História das Redes de Informação, da Idade da Pedra À Inteligência Artificial.
Portanto, precisamos de regulamentação. Isso proporciona o equilíbrio necessário para o desenvolvimento de uma IA confiável e responsável e para poder avançar nos grandes desafios para o bem da humanidade destacados por Amodei.
E, com eles, ter os mecanismos de governança necessários como um “plano para apagar incêndios”.
Empresas brasileiras estão adotando a inteligência artificial generativa (IAG) para impulsionar suas iniciativas de sustentabilidade. Um novo estudo do IBM Institute for Business Value revelou que 41% das organizações no Brasil estão usando atualmente a IA generativa (IAG) e os grandes modelos de linguagem em seus esforços de TI sustentável.
O “Sustentabilidade de TI na encruzilhada” mostrou que as empresas estão utilizando a IAG para otimizar o consumo de energia, prever emissões de carbono e otimizar a gestão de resíduos. Quase metade das empresas brasileiras, 45%, tomaram medidas para reduzir o impacto ambiental da IAG e dos grandes modelos de linguagem.
A implementação da tecnologia resulta em redução da pegada de carbono, otimização de recursos, redução de resíduos e maior eficiência energética.
“Embora a IA generativa possa ser um fator decisivo para alcançar operações de TI mais sustentáveis, impulsionar mudanças reais requer uma abordagem estratégica e sustentável”, defende o líder de Sustentabilidade da IBM Brasil, Carlos Tunes.
Segundo ele, as organizações presentes no Brasil atribuem, em média, 15,5% dos custos de energia às operações de TI, mas só 23% estão integrando avaliações de sustentabilidade durante as etapas de concepção e planejamento de projetos. “A sustentabilidade deve ser um imperativo empresarial que informe e oriente a tomada de decisões em todos os níveis e a IA também pode desempenhar um papel fundamental nisso”, declarou.
Além da IAG, as empresas estão investindo em treinamento de funcionários, incentivando práticas sustentáveis no uso de e-mail e comunicação, e utilizando soluções de nuvem híbrida e virtualização de servidores.
Outras ações incluem configurações para gerenciar a energia dos dispositivos (57%), a implementação de hardware de baixo consumo de energia (55%) e o uso de fontes de energia renováveis nos centros de dados (48%).
A pesquisa também destaca que, no Brasil, 50% das companhias receberam incentivos financeiros (por exemplo, créditos fiscais, descontos) para adotar iniciativas de sustentabilidade de TI e que 73% das organizações brasileiras disseram que a implementação de iniciativas de sustentabilidade de TI obteve impacto positivo ou significativo na eficiência operacional.
Networking e experiências práticas incríveis? Sim, o iCEV oferece! Dessa vez, as alunas de Engenharia de Software iCEV, integrantes do grupo Tech Ladies, tiveram a oportunidade de visitar a ETIPI (Empresa de Tecnologia da Informação do Piauí).
Durante a visita, elas foram recebidas por equipes da empresa, onde puderam vivenciar um dia na rotina de desenvolvedoras de software, ampliando seus entendimentos sobre o mercado e suas demandas reais.

“Sinto muito orgulho de ver todas as atividades que acontecem no iCEV. Aprendizado vai além da teoria em sala de aula, e nós fazemos isso como parte integrante da metodologia“, afirma Rayana Agrélio, CEO do iCEV.

Essa satisfação é compartilhada, inclusive, por quem vê “de fora” essas iniciativas: “fico feliz por ser uma turma de mulheres, porque a gente precisa ter a representatividade feminina nesse mundo da tecnologia. Então fico feliz por haver esse movimento e parabenizo a instituição”, diz Ellen Gera, Presidente da ETIPI. Segundo ele, o protagonismo feminino na área da tecnologia já é realidade na própria empresa que ele representa: “a casa tem ampliado o número de mulheres que participam do processo de desenvolvimento da tecnologia. E a gente espera avançar e que, no final, esses talentos possam estar aqui conosco também, nos ajudando a produzir mais tecnologia para o cidadão e para a cidadã piauiense”, continua.

Provas disso são Regla Bel e Lia Mariana, ex-alunas do curso de Engenharia de Software iCEV que, hoje, trabalham na ETIPI e que recepcionaram as Tech Ladies nesse encontro inesquecível. Diversas iniciativas ousadas são propostas pela instituição e contam com a participação de destaque dessas duas profissionais: “estamos trazendo a proposta de um desafio, uma espécie de hackathon, para trabalhar usabilidade nos serviços do gov.pi. Vamos trabalhar com o melhoramento da experiência, criação de protótipos e também incentivar as nossas alunas a trabalharem cada vez mais com a questão da experiência do usuário”, garante Regla Bel, UX/UI Designer.

As Tech Ladies aproveitaram uma programação dinâmica, repleta de aprendizados importantes e curiosidades: “tivemos primeiramente uma palestra do Presidente Ellen Gera, no auditório. Depois, fomos visitar o Centro Tecnológico, o Museu do Centro Tecnológico, e aí fomos ver o Datacenter da ETIPI. Conhecemos as equipes de desenvolvimento em cada setor”, detalha Kévilla Aguiar, estudante de Engenharia de Software iCEV.
A resposta, em parte, a este gigante desafio, passa pela inovação da próxima década: ter foco e base na Formação por Competências, com uso da Inteligência Artificial, com métricas e monitoramento das habilidades.
A grande barreira neste processo: uso inadequado da Tecnologia de Inteligência Artifical para impulsionar seu processo de seleção de forma eficiente, rápida e segura com uma IA feita sob medida para você, na medida em que tem sido fornecido com inteligência terceirizada. E a realidade mostra um significativo investimento perdido para adquirir candidatos que “nunca são vistos”.
A realidade é que em média, 85% dos currículos são pagos, mas nunca revisados por um recrutador, e isso representa despesas tremendamente ineficientes e “improdutivas”.
O objetivo a ser buscado, e é o que temos feito como propósito, ter base e foco em formação por competências, com métricas quantitativas com comparabilidade internacional, com um maior aprofundamento nas skills dos respectivos candidatos. O avanço concreto é que cada currículo de um potencial talento seja revisado, aprofundado e avaliado de maneira externa, imparcial e internacional. Aqueles que são ‘medalhistas de prata’ deveriam ser recomendados para outras funções. Sua organização deve saber quanto recebeu pelo investimento para adquirir um currículo.
O verdadeiro custo da nova tecnologia tem uma realidade de implementação com custo elevado, muitos dos quais estão ocultos e acrescentam-se aos custos da tecnologia. Urge que se estabeleçam parcerias com uma tecnologia de classificação/pontuação de IA para ver as avaliações mais aprofundadas dos candidatos.
Nesta urgência de um maior aprofundamento o iCEV e a Startup SKILLS+ respondem, em parte, a este gigante desafio, com base na Formação por Competências, com uso da Inteligência Artificial, com métricas e monitoramento das habilidades.
Com o slogan de “Formação por Competências JÁ, nas universidades e nos RH´s das empresas do Brasil”, com foco em Empregabilidade Global!
Este é seu ingresso para o futuro da formação profissional com base em competências e comparabilidade internacional.
No dia 30.05.2024, no Campus Party Weekend, da INVESTE PIAUÍ, a Startup SKILLS+ com o estratégico apoio do iCEV, fez o Lançamento dos seus primeiros inéditos produtos para o mercado de Certificação Profissional, com foco na competitividade global, em especial, com a oferta promocional de lançamento.
Todos os cursos são 100% on-line, em Português com monitoramento das habilidades, métricas quantitativas de nível global (Escala ELO Rating System de 0 a 500, nos Níveis Pré-Básico – Básico – Intermediário – Avançado) e, com a conclusão de cada curso, receber a Certificação de Competências da SKILLS+ (em dezenas de habilidades, soft e hard skills, estruturadas em grupos de atividade profissional de até seis habilidades).

Prof. Aécio Lira, Ph.D.
Coordenador do Curso de Especialização
de Gestão de Obras com Uso de Inteligência Artificial
Que tal embarcar em uma jornada imaginativa com Tiradentes, o visionário líder da Inconfidência Mineira, neste Dia de Tiradentes? Vamos explorar como as tecnologias modernas poderiam ter potencializado sua luta pela liberdade e justiça!
Imagine se Tiradentes, o líder visionário da Inconfidência Mineira, tivesse acesso às tecnologias modernas que temos hoje. Seus ideais de liberdade e justiça teriam encontrado novos horizontes para se manifestarem e inspirarem?
Com a disseminação rápida de informações proporcionada pela internet, Tiradentes poderia mobilizar e unir pessoas de todo o país em prol de sua causa. Redes sociais se tornariam ferramentas poderosas para conectar os insatisfeitos com o sistema, permitindo a organização de protestos pacíficos e a disseminação de ideias libertárias.
O uso de smartphones e aplicativos de mensagens instantâneas permitiria uma comunicação mais eficiente e segura entre os conspiradores, tornando mais difícil para o governo reprimir suas atividades. Além disso, a criptografia moderna garantiria que suas mensagens permanecessem confidenciais, protegendo-os da vigilância do Estado.

As plataformas de crowdfunding ofereceriam uma maneira de arrecadar fundos para financiar a revolução sem depender de financiamento estatal ou de grandes doações, tornando o movimento mais independente e resistente à corrupção.
Tiradentes também poderia usar a realidade virtual para simular cenários e estratégias de batalha, permitindo que seus seguidores se preparassem melhor para confrontos com as forças do governo. Além disso, a impressão 3D poderia ser utilizada para fabricar equipamentos de forma descentralizada e acessível.
Em resumo, as tecnologias atuais teriam potencializado os intuitos revolucionários de Tiradentes, permitindo-lhe mobilizar mais pessoas, comunicar-se de forma segura, arrecadar fundos de maneira independente e preparar-se melhor para confrontos.
Agora, é sua vez de imaginar: como você acha que a história teria sido diferente se Tiradentes tivesse acesso a essas tecnologias? Como outras datas marcantes da história teriam sido influenciadas pelas tecnologias modernas?
É difícil pensar em serviços e atividades que não envolvam a Internet. Até mesmo aqueles que podem, em um primeiro momento, parecer desconectados, está ainda que minimamente dependente da ligação de um equipamento a uma rede de data centers ou servidores na nuvem.
Um cenário que torna a gestão desse tipo de infraestrutura ainda mais significativa, afinal poucos minutos de downtime podem representar a perda de milhões em vendas, abertura para cibercriminosos e até mesmo acidentes.
Em contrapartida, a crescente sofisticação dos sistemas e soluções utilizados no dia a dia das empresas exige que o TI amplie as tecnologias que apoiem a execução de operações sem interrupções, como Inteligência Artificial, Big Data e Analytics, algo que deve seguir um fluxo adequado de progressão, evitando que a visibilidade de toda a infraestrutura fique comprometida.
A observabilidade surge como uma resposta a essa necessidade de visibilidade e insights genuínos sobre o desempenho dos sistemas de tecnologia. Ao longo das últimas décadas, empresas e profissionais de TI mantinham sets específicos de soluções de monitoração dependendo da tecnologia implementada, hoje porém, com operações mais complexas, é preciso estabelecer a rápida absorção de informações para tomar decisões em tempo real.
Com isso, a observabilidade atua de maneira integrada aos objetivos de TI e também de negócios das empresas, garantindo resiliência para a aceleração da inovação.
Alguns pontos proporcionados:
A adição de Observabilidade Full Stack Gerenciada (Managed FSO) otimiza ou elimina a realização de tarefas manuais que consomem horas e horas de trabalho, aumentando a produtividade das equipes de TI e garantindo que erros não sejam cometidos.

Além das questões de segurança relacionadas à responsabilidade sobre os dados, uma abordagem de observabilidade também diminui a probabilidade de ataques cibernéticos que poderiam comprometer as operações da empresa e causar danos significativos aos sistemas em larga escala.
Sistemas bancários, grandes redes de varejo e e-commerces são claros exemplos de empresas que podem sofrer graves perdas com falhas e bugs no sistema. Nesses casos, a observabilidade atua como uma barreira efetiva contra possíveis problemas com respostas rápidas sem causar complicações perceptíveis aos usuários.
De que maneira é possível aprimorar os negócios? A visão completa proporcionada pela observabilidade é fundamental nesse processo. As análises e diagnósticos oriundos do managed FSO oferecem insights valiosos, permitindo uma tomada de decisões estratégica e direcionada para que líderes possam gerar valor relevante para uma organização.
Em comparação com outras soluções de monitoramento, o Managed Full-Stack Observability (FSO) oferece visibilidade entre plataformas, flexibilidade para evolução, visão única e simplificada, otimização de aplicativos de missão crítica, gerenciamento estratégico e suporte especializado.
A adesão de plataformas de observabilidade é indispensável para empresas que buscam enfrentar os desafios da transformação digital com eficiência. Com uma estratégia bem implementada, as organizações podem automatizar operações, reduzir riscos, melhorar a experiência do cliente e obter insights estratégicos para impulsionar o crescimento.
A NEC, em parceria com a Cisco, oferece soluções completas de Managed FSO, garantindo visibilidade máxima e suporte especializado para operações ágeis e seguras. Para empresas que buscam se destacar no mercado digital, investir em observabilidade é o caminho certo para o sucesso.
Artigo original de: Eduardo Ribeiro. Publicado em: https://teletime.com.br/. Disponível: aqui.
As relações comerciais da sociedade passaram a ter uma companhia que já era prevista em 1990, mas não em tamanha intensidade. O surgimento da internet, dos computadores e dos celulares mudou a forma como as pessoas se comunicam, trabalham e se divertem. Desde então, essa tecnologia sempre esteve presente no dia-a-dia das pessoas, e o imediatismo que ela fornecia se tornou algo costumeiro em nossas interações.
No quesito da prestação de serviços, esse imediatismo deixou de ser uma qualidade e se tornou um defeito, já que por se tratarem de pessoas reais, que precisam separar o tempo de trabalhar e descansar, sempre havia um horário certo para oferecer seus serviços. Assim, devido à falta de paciência por respostas, e pelo imediatismo ter se tornado um padrão na sociedade, a implementação de assistentes virtuais surgiu como uma alternativa para essas questões. As primeiras a existirem foram a Alexa, da Amazon, e a Siri, da Apple, ambas sendo softwares que respondem a comandos de voz.

Segundo uma pesquisa da Ilumeo em setembro de 2022, 91% dos brasileiros já utilizam assistentes virtuais de voz, tendo um aumento de 4% em relação aos últimos dois anos. Essa interação tem impactado positivamente as relações entre clientes e empresas, influenciando a forma como as pessoas se relacionam com as marcas.
Dalson De Carvalho, usuário dessa forma de tecnologia, relata que teve uma experiência positiva ao utilizar assistentes virtuais.” É como se você entrasse em uma loja e fosse bem recebido por alguém, que sempre terá uma resposta gentil e educativa para qualquer coisa que você disser. É um super funcionário que entende o que você precisa e faz você se sentir valorizado e compreendido. Isso deixa uma impressão positiva, alimentando a lealdade do cliente com a empresa”, diz.
Ele conta que é uma experiência divertida e agradável, já que as assistentes são capazes de realizar tarefas como configurar lembretes, responder a perguntas e controlar dispositivos inteligentes em casa. Para ele, a inteligência artificial (I.A), torna a interação com aplicativos mais fácil e intuitiva, permitindo que os softwares aprendam com suas preferências e comportamentos, adaptando-se para oferecer uma experiência personalizada.
Com o avanço da tecnologia, principalmente da área de inteligência artificial, surgem os influenciadores digitais, que são avatares 3D criados para dar personalidade a uma marca. A evolução dos softwares permitiu a criação de personagens digitais realistas e interativos, capazes de interagir com seguidores, promover marcas e produtos, e até mesmo participar de campanhas publicitárias. A popularidade deles se relaciona à capacidade de representar ideais à sua habilidade de engajar o público de maneira única, com uma nova forma de narrativa e entretenimento nas redes sociais
As assistentes virtuais surgiram como um recurso adicional capaz de atender às demandas dos clientes sem que eles precisem passar por longas esperas. Na internet, tudo é rápido e fácil, então os consumidores buscam essa agilidade nas empresas, desejando respostas rápidas para suas necessidades, independente do horário, já que essas assistentes pessoais estão disponíveis para atendê-los 24 horas por dia. Um exemplo consolidado é a Lu, do Magazine Luiza, que foi criada para ser uma assistente virtual e que com a com a receptividade do público, tornou-se também uma influenciadora nas redes sociais da marca.

Em entrevista para o portal Luneta, Odilo Queiroz, CEO da Medi Branding & Network, avisa que não tem nada de novo nessa humanização de assistentes virtuais e que, na verdade, há muito tempo as empresas vêm fazendo isso. O que está acontecendo é que a tecnologia das I.A tornaram disponíveis outros métodos de atendimento comercial, como sistemas complexos de automação. Ele afirma também que essa humanização das assistentes virtuais faz parte de uma estratégia comercial, não para “enganar” o consumidor, fazendo-o achar que se trata um de um humano, mas sim para quebrar a objeção de ser atendida por uma IA. E tudo isso faz parte de uma estrutura de copywriting.
Odilo acredita que a humanização das assistentes virtuais pode impactar na experiência do cliente. Segundo ele, existem estudos que mostram que, se a loja responde nos primeiros minutos após receber a mensagem, a taxa de conversão é maior do que nas que demoram mais tempo.“Às vezes, o empreendedor, de madrugada, recebe uma dúvida de um potencial cliente e como não está no horário comercial, não tem ninguém para responder. Perde a venda! E quem nunca comprou nada de madrugada? Todo mundo compra”, comenta.
Ele ainda pontua que pensar na experiência de consumo do cliente, com uma estratégia de automação bem feita e organizada, pode muitas vezes ser o suficiente para tirar dúvidas e encaminhar a pessoa ao setor correto, tudo isso de forma mais fluída. “Quando você vende o seu produto ou seu serviço na internet, é muito mais comum você receber uma mensagem de um curioso do que de um comprador. Claro que você tem que otimizar o seu negócio pensando na venda e na experiência do usuário, então as assistentes virtuais vão se tornar cada vez mais comuns, até como um “filtro” de curioso, para que o empresário consiga otimizar a sua abordagem comercial”. Essa questão varia de acordo com a maneira na qual a tecnologia é utilizada.
A humanização das assistentes virtuais está sendo aplicada de maneira diferente em setores específicos, afinal elas são projetadas para entender as necessidades individuais dos clientes, adequando a realidade de cada empresa. Essa tecnologia está redefinindo como as empresas interagem com seu público, permitindo comunicações mais rápidas e eficazes. Existem diferentes aspectos em cada tipo de negócio, assim como diferentes momentos em que o assistente pode ser aplicado. A assistente virtual de um hospital tem uma estrutura totalmente diferente de uma assistente virtual de um banco. São duas estruturas de negócio distintas, isso reflete também nas suas abordagens.
Apoena Paiva, gestora de marketing, explica que para construir a identidade da marca, a assistente virtual precisa unir a essência da marca e dos consumidores. É preciso saber quais características, necessidades, desejos e sonhos dos clientes, assim como a missão da empresa e valores. Desse modo, a inteligência artificial passa uma imagem real da empresa, o rosto da marca e o comportamento, construindo uma relação entre ambos.
Ela comenta que as assistentes são programadas para fornecer respostas que demonstrem empatia, reconhecendo emoções expressas pelo usuário. Isso cria uma interação mais natural e amigável, aproximando a experiência digital da riqueza emocional presente nas conversas humanas, tornando o cliente mais suscetível à compra. Elas estão moldando a forma como experimentamos o mundo digital, adicionando camadas de empatia, personalização e compreensão emocional que prometem revolucionar as interações tecnológicas no presente e no futuro. Apesar de todas as facilidades que a introdução da IA causa, existem muitos problemas a serem resolvidos.
As assistentes virtuais surgem como agentes transformadores, trazendo consigo uma série de aspectos que moldam de forma positiva a nossa sociedade. Dimmy Magalhães, é o coordenador da Escola de Tecnologia da Faculdade iCEV, além de analista de sistemas e P.h.D. em Ciência da Computação, e destaca quais são esses aspectos.”As vantagens são enormes. Com a população cada vez mais envelhecida, para os idosos essas tecnologias mais humanas e empáticas podem fornecer companhia e diminuir sentimentos de solidão e isolamento. Por outro lado, essa humanização traz melhorias na experiência do usuário, na medida em que a interação mais fácil pode diminuir o abismo entre o desenvolvimento tecnológico e as pessoas sem tanta aproximação com a tecnologia”, explica.

Dimmy alerta que, apesar das vantagens na humanização dessas tecnologias, ela também possui seus pontos negativos.”A principal desvantagem que eu enxergo é a perda de privacidade. Esses sistemas têm uma necessidade maior de coleta de dados para gerar uma interação mais cooperativa com os usuários. Essa troca pode ter dois aspectos. O primeiro são sistemas mais adaptados à necessidade do usuário, e o segundo é o uso de dados que viram produtos para outras empresas, tornando a privacidade um elo fraco nesse ecossistema”, afirma.
Apesar de serem ferramentas importantes para o atendimento em várias empresas, algumas pessoas mantêm uma certa desconfiança em relação às assistentes virtuais, principalmente devido a preocupações sobre segurança e privacidade. Para resolver essa questão, Dimmy destaca a necessidade das empresas garantirem que os dados não contenham aspectos que possam comprometer o funcionamento adequado e a integridade das respostas fornecidas por essas assistentes virtuais.
Além disso, ele comenta que há necessidade de investir em sistemas de segurança. Políticas claras de privacidade e transparência são fundamentais para tranquilizar os usuários quanto à segurança e ao uso ético de seus dados. Segundo o analista de sistemas, é crucial a implementação de tecnologias de segurança de ponta, como criptografia avançada, para proteger os dados. A empresa deve armazenar apenas as informações necessárias para fornecer o serviço, ou seja, dados sensíveis devem ser criptografados ponta a ponta ou nem mesmo coletados. Isso possibilitará a minimização da exposição.
De acordo com Dimmy Magalhães, no futuro ele acredita que as assistentes virtuais estarão cada vez mais integradas à espécie humana, a ponto de realizar atividades repetitivas ou prioritárias de forma automatizada.“Não é incomum que residências atualmente possuam assistentes como a Alexa, responsáveis por controlar desde as luzes até o aspirador de pó. Isso não apenas assegura uma economia energética, mas também prioriza as atividades, proporcionando aos humanos mais tempo para conviver e viver em comunidade”, finaliza.
As assistentes virtuais mudaram a maneira como interagimos com a tecnologia ao otimizar o trabalho em diversas áreas. Elas oferecem suporte em tempo real, permitindo uma interação mais natural e intuitiva com dispositivos e serviços. No entanto, é importante considerar questões éticas e de segurança relacionadas ao desenvolvimento e uso das IA, garantindo que seu impacto seja positivo e benéfico para toda a sociedade. Em um futuro próximo, a colaboração entre a tecnologia e a humanização promete não apenas redefinir a forma como nos relacionamos com esses agentes virtuais, mas também elevar o nível dessa experiência, transformando o mundo atual em uma realidade repleta de possibilidades.
Por: Isabelle Lima e Camila Mineiro. Disponível em: https://portalluneta.com.br/2024/02/01/a-humanizacao-de-marcas-e-empresas-atraves-da-inteligencia-artificial/.
No domínio dinâmico da Tecnologia da Informação (TI), ficar atento às tendências globais é fundamental para prosperar em um cenário cada vez mais competitivo. Esta consciência não trata apenas de garantir a empregabilidade, mas de um movimento estratégico para capitalizar oportunidades de negócios emergentes. Por isso, este artigo mergulha nos insights mais recentes do Gartner, Inc., revelando as principais tendências tecnológicas para 2024.
Este direcionamento não só capta o pulso da inovação tecnológica, mas também delineia as áreas-chave nas quais os profissionais de TI precisarão canalizar os seus conhecimentos para obter o máximo impacto.
Hoje, sabemos que a atualização das equipes é vital para que as organizações possam alinhar estrategicamente os seus conjuntos de competências, com base nas forças transformadoras que impulsionam a indústria, estabelecendo-se como colaboradores indispensáveis para o sucesso organizacional.
Navegue pelas complexidades da inteligência artificial generativa democratizada, da confiança, do gerenciamento de riscos e da segurança da IA, além do desenvolvimento ampliado pela IA e de outras tendências transformadoras. Saiba mais a seguir:
De acordo com as previsões do Gartner, em 2024 haverá um aumento de 8% nos investimentos mundiais com TI, com gastos chegando a um montante total de US$ 5,1 trilhões. Diante desse cenário, estar atento às novidades que prometem movimentar o mercado global nos próximos meses assume uma importância acrescida.
Diante de disrupções, os líderes de TI são estimulados a agir de forma ousada e estratégica para aumentar a resiliência das suas operações. Para isso, o Gartner lançou recentemente seu tão aguardado relatório sobre as tendências para o próximo ano (Top Strategic Technology Trends for 2024), apresentando um panorama para que as organizações naveguem neste cenário tecnológico em evolução.
As principais indicações destacam as tecnologias que irão gerar oportunidades significativas para os CIOs e outros gestores nos próximos 36 meses.
“Os líderes de TI estão em uma posição única para estabelecer estrategicamente um roteiro onde os investimentos em tecnologia ajudam a sustentar o sucesso dos negócios em meio às incertezas e pressões”, explicou Bart Willemsen, analista vice-presidente da Gartner.
Conheça, a seguir, as 10 principais tendências tecnológicas estratégicas para 2024:

A inteligência artificial generativa (GenAI) está se democratizando pela convergência de modelos massivamente pré-treinados, como a computação em nuvem e o código aberto, tornando estes modelos acessíveis a trabalhadores em todo o mundo.
Por isso, até 2026, o Gartner prevê que mais de 80% das organizaçõess terão usado APIs e modelos de GenAI e/ou implantado aplicações habilitadas por esta tecnologia em ambientes de produção, contra menos de 5% no início de 2023.
As aplicações baseadas em generative AI podem tornar vastas fontes de informações – internas e externas – acessíveis e disponíveis para usuários empresariais. Isso significa que a rápida adoção da GenAI democratizará significativamente o conhecimento e as competências na empresa.
Grandes modelos de linguagem permitem que as companhias conectem seus trabalhadores ao conhecimento em um estilo conversacional, com uma rica compreensão semântica.
A democratização do acesso à IA tornou a necessidade da Gestão de Confiança, Risco e Segurança da IA (AI Trust, Risk and Security Management – TRiSM) ainda mais urgente e clara. Sem barreiras de proteção, os modelos de IA podem gerar rapidamente efeitos negativos agravados que ficam fora de controle, ofuscando qualquer desempenho positivo e ganhos sociais que a IA permite.
A AI TRiSM fornece ferramentas para ModelOps, proteção proativa de dados, segurança específica de IA, monitoramento de modelo (incluindo monitoramento de desvio de dados, desvio de modelo e/ou resultados não intencionais) e controles de risco para entradas e saídas para modelos e aplicativos de terceiros.
O Gartner prevê que, até 2026, as empresas que aplicam controles baseados em AI TRiSM aumentarão a precisão da sua tomada de decisão, eliminando até 80% de informações defeituosas e ilegítimas.
O desenvolvimento aumentado por IA é o uso de tecnologias de inteligência artificial, como GenAI e aprendizado de máquina, para auxiliar engenheiros de software no projeto, codificação e teste de aplicações.
A engenharia de software assistida por IA melhora a produtividade do desenvolvedor e permite que as equipes atendam à crescente demanda para administrar os negócios.
Além disso, tais ferramentas de desenvolvimento baseadas em IA permitem que os engenheiros de software gastem menos tempo escrevendo código, para que possam dedicar mais tempo a atividades estratégicas, como o design e a composição de aplicações de negócios atraentes.
As chamadas intellligent applications incluem a inteligência – que o Gartner define como adaptação aprendida para responder de forma adequada e autônoma – como uma competência. Essa habilidade pode ser aplicada em muitos casos de uso para melhorar ou automatizar o trabalho.
Como capacidade fundamental, a inteligência em aplicações compreende diversos serviços baseados em inteligência artificial, tais como aprendizado de máquina, armazenamento de vetores e dados conectados. Consequentemente, proporcionam experiências que se adaptam dinamicamente ao usuário.
Existe uma clara necessidade e demanda por aplicações inteligentes. Na pesquisa Gartner CEO and Senior Business Executive de 2023, 26% dos CEOs citaram a escassez de talentos como o risco mais prejudicial às organizações. Atrair e reter talentos é a prioridade da força de trabalho, enquanto a IA foi eleita a tecnologia que terá um impacto mais significativo em seus setores de atuação nos próximos três anos.
A força de trabalho conectada aumentada (augmented-connected workforce – ACWF) é uma estratégia empregada para otimizar o valor derivado dos trabalhadores humanos. A necessidade de acelerar e dimensionar talentos está impulsionando essa tendência.
O modelo se utiliza de aplicações inteligentes e de análises da força de trabalho para fornecer contexto diário e a orientação para apoiar a experiência, o bem-estar e a capacidade das equipes de desenvolverem as próprias competências. Ao mesmo tempo, o ACWF impulsiona resultados empresariais e impacto positivo para as principais partes interessadas.
Assim, o Gartner estima que, até 2027, 25% dos CIOs usarão iniciativas de força de trabalho conectada aumentada para reduzir o tempo de aquisição de competência em 50% para funções-chave.
O gerenciamento contínuo de exposição a ameaças (continuous threat exposure management – CTEM) é uma abordagem pragmática e sistêmica que permite às organizações avaliar a acessibilidade, exposição e explorabilidade dos ativos digitais e físicos de uma companhia de forma contínua e consistente.
Alinhar os escopos de avaliação e remediação do CTEM com vetores de ameaças ou projetos de negócios, em vez de um componente de infraestrutura, traz à tona não apenas as vulnerabilidades, mas também ameaças incorrigíveis.
Até 2026, o Gartner prevê que as organizações que priorizarem seus investimentos em segurança com base em um programa CTEM perceberão uma redução de dois terços nas violações.
Os clientes-máquina (machine customers, também chamados de custobots) são atores econômicos não humanos capazes de negociar e adquirir autonomamente bens e serviços em troca de pagamento. Até 2028, existirão 15 mil milhões de produtos conectados com potencial para se comportarem como clientes, com mais bilhões a seguir nos próximos anos.
Esta tendência de crescimento será a fonte de trilhões de dólares em receitas até 2030 e acabará por se tornar mais significativa do que a chegada do comércio digital. As considerações estratégicas devem incluir oportunidades para facilitar estes algoritmos e dispositivos, ou mesmo criar novos custobots.

Imagem de rorozoa no Freepik
A tecnologia sustentável é uma estrutura de soluções digitais utilizadas para habilitar resultados ambientais, sociais e de governação (ESG), que apoiam o equilíbrio ecológico e os direitos humanos a longo prazo.
A utilização de tecnologias como a inteligência artificial, a criptomoeda, a Internet das Coisas e a computação em nuvem está gerando preocupações sobre o consumo de energia e os impactos ambientais relacionados. Isto torna mais crítico garantir que a utilização das TI se torne mais eficiente, circular e sustentável.
Na verdade, o Gartner prevê que, até 2027, 25% dos CIOs verão a sua remuneração pessoal ligada ao impacto tecnológico sustentável.
Engenharia de plataforma é a disciplina de construção e operação de plataformas de desenvolvimento interno de autoatendimento. Cada plataforma é uma camada, criada e mantida por uma equipe de produto dedicada, projetada para dar suporte às necessidades de seus usuários por meio da interface com ferramentas e processos.
O objetivo da engenharia de plataforma é otimizar a produtividade, a experiência do usuário e acelerar a entrega de valor comercial.
Até 2027, o Gartner prevê que mais de 70% das empresas usarão plataformas de nuvem industriais (industry cloud platforms – ICPs) para acelerar suas iniciativas de negócios, contra menos de 15% em 2023.
As ICPs abordam resultados de negócios relevantes para o setor, combinando soluções SaaS, PaaS e IaaS subjacentes em uma oferta completa de produtos com recursos combináveis. Isso normalmente inclui uma estrutura de dados do setor, uma biblioteca de pacotes de recursos de negócios, ferramentas de composição e outras inovações de plataforma. São propostas de nuvem personalizadas específicas para um setor e podem ser adaptadas às necessidades de uma organização.
À medida que as empresas navegam no cenário tecnológico em evolução, compreender e adotar estas tendências tecnológicas estratégicas pode abrir caminho para a resiliência, a inovação e o sucesso do negócio, sustentado numa era de rápido avanço tecnológico.
Diante deste cenário, os profissionais de TI são encorajados a avaliar os impactos e benefícios destas indicações, reconhecendo a necessidade de uma abordagem disciplinada para aproveitar todo o potencial das tecnologias emergentes.
“Os executivos devem avaliar os impactos e benefícios das tendências tecnológicas estratégicas; mas esta não é uma tarefa fácil, dada a taxa crescente de inovação tecnológica”, afirmou Chris Howard, analista vice-presidente e chefe de pesquisas do Gartner. “Por exemplo, a IA generativa e outros tipos de IA oferecem novas oportunidades e impulsionam diversas tendências. Obter valor comercial a partir do uso duradouro da IA requer uma abordagem disciplinada para a adoção generalizada, juntamente com atenção aos riscos”, conclui.
Artigo encontrado em: https://odatacolocation.com/blog/gartner-principais-tendencias-tecnologicas-para-2024/
Antes de adentrarmos nas complexidades técnicas da inteligência artificial (IA), é imperativo compreender o lugar dessa tecnologia no contexto humano. A tecnologia, incluindo a IA, não é apenas uma ferramenta, mas uma extensão de nossa capacidade de criar e inovar, transformando fundamentalmente a maneira como vivemos, trabalhamos e interagimos uns com os outros. No entanto, essa transformação é acompanhada por desafios éticos e sociais
que precisam ser abordados com uma abordagem humanista e realista.

No contexto humano, a tecnologia e, em particular, a IA, desempenham um papel ambivalente. Por um lado, a IA pode aprimorar significativamente nossa qualidade de vida, aumentar a eficiência em diversas áreas, como medicina, finanças e transporte, e até mesmo salvar vidas através de diagnósticos médicos mais precisos e tratamentos personalizados. No entanto, por outro lado, ela levanta questões preocupantes, como a privacidade de dados, a segurança cibernética e o temido desemprego tecnológico, à medida que sistemas automatizados substituem certas funções de trabalho.
Aqui, a filosofia humanista possui um papel crucial. O humanismo coloca o indivíduo no centro de suas preocupações, enfatizando o valor intrínseco de cada ser humano. Essa filosofia defende a ética, a razão e o respeito pelos direitos humanos como princípios fundamentais. No contexto da IA, o humanismo nos lembra da importância de desenvolver e utilizar essa tecnologia de forma responsável, considerando sempre seu impacto nas pessoas. Isso significa garantir que os algoritmos de IA sejam justos, transparentes e não discriminatórios, e que o uso dos dados seja feito com respeito à privacidade e à dignidade dos indivíduos.

Além disso, o humanismo também ressalta a importância da educação e do acesso equitativo à tecnologia. À medida que a IA se torna mais onipresente, é vital que todos tenham a oportunidade de entender e se envolver com essa tecnologia, para que possamos colher seus benefícios de forma igualitária e construir uma sociedade mais justa. No entanto, enquanto abraçamos o humanismo, também devemos adotar uma abordagem realista em relação à IA. O realismo nos lembra de que a tecnologia, incluindo a IA, não é uma panaceia para todos os problemas humanos. Ela pode apresentar limitações e desafios, como o viés nos algoritmos e a dependência excessiva de sistemas automatizados. Para lidar com essas questões, precisamos de uma abordagem equilibrada e pragmática.
No contexto da IA, o realismo nos incentiva a reconhecer os riscos e limitações da tecnologia e a trabalhar proativamente para mitigá-los. Isso envolve a implementação de regulamentações adequadas, o desenvolvimento de estratégias de segurança cibernética e a contínua monitorização dos sistemas de IA para detectar e corrigir possíveis vieses ou erros. De forma geral, a Inteligência Artificial é um campo multidisciplinar que busca criar sistemas e máquinas capazes de realizar tarefas que, normalmente, exigiriam inteligência humana, como aprendizado, raciocínio, tomada de decisões e reconhecimento de padrões. No
entanto, quando pensamos em IA de forma utópica, podemos ser tentados a imaginar máquinas dotadas de consciência e autoconhecimento, capazes de replicar plenamente a complexidade da mente humana.

Esse idealismo muitas vezes é retratado na ficção científica, na qual a IA assume características quase mágicas, como compreensão emocional, criatividade ilimitada e uma compreensão profunda da natureza humana. Embora essas representações sejam fascinantes, é importante lembrar que a IA atual está longe de atingir esse nível de sofisticação, sendo, na realidade, um conjunto de algoritmos e sistemas projetados para executar tarefas específicas com base em dados e regras programadas.
O conceito quase distópico da IA se distancia da realidade técnica, destacando a importância de abordagens humanistas e realistas em seu desenvolvimento e aplicação. Enquanto o humanismo nos lembra do valor intrínseco da humanidade e da ética na utilização da IA, o realismo nos orienta a encarar a tecnologia com objetividade, reconhecendo suas limitações e desafios. Em meio às expectativas utópicas, é essencial mantermos uma visão equilibrada da IA, reconhecendo-a como uma ferramenta poderosa, porém, que ainda está em evolução, e que sua aplicação deve ser guiada por valores éticos e uma compreensão realista de suas capacidades atuais. Assim, podemos buscar benefícios tangíveis e, ao mesmo tempo, enfrentar os desafios complexos que a IA apresenta à nossa sociedade.
Para ilustrar, suponha que você deseja um assistente virtual em sua casa para ajudar com tarefas diárias. O idealismo hollywoodiano seria ter um assistente que não só executa suas ordens, mas também compreende suas emoções, sugere atividades com base em suas preferências e até mesmo faz piadas para animar seu dia. Esse assistente, na visão futurista, seria como um amigo virtual perfeito, sempre atento às suas necessidades e desejos.
No entanto, na realidade, a IA atualmente disponível é mais semelhante a um assistente robótico prático, como um aspirador de pó autônomo. Ele pode realizar tarefas específicas, como limpar o chão de forma eficaz, mas não possui consciência, emoções ou capacidade de compreender profundamente seus sentimentos. Ele não pode fazer sugestões criativas nem entender suas nuances emocionais.

Sistemas como o ChatGPT se aproximam muito mais de um “assistente robótico prático” do que de uma entidade com consciência e compreensão emocional. Isso ocorre devido às limitações tecnológicas subjacentes a essas tecnologias. O ChatGPT e sistemas similares operam com base em algoritmos de aprendizado de máquina e processamento de linguagem natural, o que lhes permite gerar respostas contextuais e úteis, mas sem consciência, sentimentos ou uma verdadeira compreensão do mundo e das emoções humanas.
Eles funcionam a partir de padrões estatísticos aprendidos a partir de dados, fornecendo soluções práticas para tarefas específicas, mas não são capazes de replicar a complexidade da mente humana. Portanto, ao considerarmos o uso da IA, é importante manter expectativas realistas sobre suas capacidades e limitações, reconhecendo sua utilidade prática, mas também sua ausência de consciência e emoção.
Em um mundo onde a tecnologia, em particular a Inteligência Artificial, desempenha um papel cada vez mais central, é vital que adotemos uma abordagem humanista e realista para sua utilização. O humanismo nos recorda da importância de colocar os valores humanos, a ética e o respeito pelos direitos individuais no centro de nossas ações, garantindo que a IA seja desenvolvida e aplicada de maneira responsável, justa e equitativa. Além disso, o realismo nos
lembra de reconhecer as limitações e desafios dessa tecnologia, sem cair em idealizações utópicas.
À medida que a IA continua a desempenhar um papel cada vez mais significativo em nossa sociedade, devemos permanecer vigilantes, garantindo que essa ferramenta poderosa seja usada para melhorar nossas vidas e enfrentar os problemas complexos que enfrentamos. Devemos promover a transparência, regulamentação adequada e educação para que todos tenham a oportunidade de compreender e se envolver com a IA.

O verdadeiro perigo da Inteligência Artificial não reside em uma possível dominação física em escalas mundiais, como frequentemente retratado na ficção científica, mas sim na possibilidade de um uso desgovernado, inconsciente, incontrolável e socialmente deslocado dessa tecnologia. O risco iminente não é uma rebelião de máquinas, mas sim a potencial criação de uma lacuna social insuperável. Um uso inadequado da IA pode resultar em uma desconexão devastadora entre o avanço tecnológico e as necessidades humanas básicas.
Pode criar uma sociedade onde a tecnologia avança rapidamente, enquanto muitos são deixados para trás, tanto digital quanto socialmente. Esta disparidade pode gerar uma avalanche de desabrigados sociais e digitais, marginalizando indivíduos e comunidades inteiras que não têm acesso às oportunidades proporcionadas pela IA. Portanto, é imperativo que avancemos na implementação da IA com consciência, responsabilidade e consideração pelas implicações humanas, garantindo que essa tecnologia beneficie a humanidade como um todo, em vez de aprofundar ainda mais as divisões em nossa sociedade.


O Tribunal de Justiça do Piauí (TJ-PI) lançou, o sistema JuLIA (Justiça AuxiLiada pela Inteligência Artificial). O objetivo desse projeto é otimizar a rotina do tribunal e automatizar tarefas, trazendo maior eficiência e acessibilidade à Justiça.
Desenvolvido pelo Laboratório de Inovação do Tribunal, o OpalaLab, a JuLIA é uma solução computacional projetada para aprimorar os processos jurídicos.
 A IA foi desenvolvida sob supervisão do nosso professor e coordenador de Engenharia de Software, Dimmy Magalhães , a IA está em funcionamento desde o dia 11 de outubro. Mais um exemplo de como a IA pode facilitar a nossa vida.
A IA foi desenvolvida sob supervisão do nosso professor e coordenador de Engenharia de Software, Dimmy Magalhães , a IA está em funcionamento desde o dia 11 de outubro. Mais um exemplo de como a IA pode facilitar a nossa vida.
De acordo com Dimmy Magalhães, servidor do OpalaLab, o sistema JuLIA é resultado de nove meses de trabalho e contempla tanto a otimização dos processos internos do tribunal quanto a melhoria no atendimento aos juízes e partes envolvidas.
“Nós definimos a JuLIA como um conjunto de soluções de inteligência computacional que trabalha coordenado, visando melhorar a eficiência e a acessibilidade da justiça piauiense”, destacou.
O sistema é composto por quatro áreas principais: processual, análise de dados, acesso à informação e comunicação ativa.
A principal função do sistema é a comunicação ativa, integrada ao WhatsApp. A ferramenta permite que a Justiça se comunique de maneira rápida e eficiente, assemelhando-se ao modelo do ChatGPT. Ela tem a capacidade de responder questões sobre o próprio Tribunal, a base de dados do sistema está alimentada com 2,2 bilhões de dados.
Por meio do uso de inteligência artificial e processamento de linguagem fácil, a JuLIA fornece informações sobre o tribunal e o progresso dos processos.
Uma das funcionalidades é a intimação automática. O módulo de intimação da JuLIA identifica qualquer julgamento, colegiado ou monocrático, calcula o prazo de Intimação e movimenta o processo no PJe. Os processos serão intimados automaticamente em menos de 24 horas no projeto piloto.
Dimmy Magalhães destaca que processos que demoravam até um ano para serem baixados, agora são identificados e baixados em poucos dias. Além disso, a JuLIA irá contribuir para reduzir custos, melhoria das métricas de qualidade da prestação jurisdicional e maior proximidade com a população.

As startups vêm diversificando suas atuações para atender nichos específicos de mercado, para além dos formatos tradicionais. Diversos setores estão fazendo uso dos recursos tecnológicos para trazer inovações em suas áreas. No ramo da educação, as edtechs (empresas de tecnologia voltadas para o setor educacional) vem ganhando espaço.
De acordo com um mapeamento realizado pelo Centro de Inovação para a Educação Brasileira (CIEB) e a Associação Brasileira de Startups (Abstartup), existem 364 edtechs no Brasil, espalhadas por 25 estados brasileiros, atuando principalmente na educação básica. A Associação Brasileira de Startups define as edtechs como startups que fazem o uso de alguma forma da tecnologia, como facilitadora de processos de aprendizagem e aprimoramento dos sistemas educacionais.
Presidente da organização, Amure Pinho explica que o mercado das edtechs tem mostrado um grande potencial de desenvolvimento. “Inclusive é o segundo maior mercado de startups, perdendo apenas para as fintechs. Temos uma população gigantesca e durante muitos anos houve um grande incentivo e apoio governamental na formação acadêmica”, aponta. O potencial das edtechs é tão grande que o setor cresce, em nível mundial, 17% ao ano, e deve faturar US$ 252 bilhões até 2020, segundo o relatório EdTechXGlobal.
O empreendedor Jan Krutzinna é o CEO da EduSim, edtech voltada para melhorar o ensino de inglês na educação básica. “A educação é minha paixão porque caminha com minha história pessoal e abre muitas portas para as pessoas. Essa área chama muito atenção em termos de idealismo por causa do contato humano. Existe uma necessidade de aumentar as habilidades das pessoas cada vez mais porque as economias estão ficando mais sofisticadas e demandando mais dos profissionais”, observa.
Para Jan, essa exigência maior é uma tendência positiva para o setor educacional. “Temos muitas pessoas querendo colaborar. O que importa é trazer pessoas com experiência em sala de aula, que conheçam a realidade de um professor e a consigam traduzir em produtos digitais. Eu vejo um potencial realmente enorme nas edtechs se conseguirmos alinhar as forças entre o governo e setor privado”, pondera.

CEO da Trybe, escola voltada para as profissões digitais mais procuradas pelo mercado de trabalho, Matheus Goyas já possuía experiência nos setores de tecnologia e educação quando se juntou com amigos de infância para observar os desafios da educação conectados a transformação do mundo digital.
“Vimos o mundo passando por uma mudança de paradigma econômico, mas sem ter a mão de obra necessária para atender essa demanda. No Brasil, o problema é ainda maior por não ter formação em digital skills. Temos uma grande número de pessoas desempregadas e sem qualificação e empresas que não conseguem contratar. Isso prejudica o desenvolvimento do país”, salienta.
Matheus percebe que as pessoas, em geral, estão se conscientizando que é a educação é a pauta do momento. “Nos empreendedores não têm refletido tanto como na população, porque existem outros setores mais atrativos. Mas tem gente apaixonada atuando na área, mas ainda não é a agenda de preferência dos empreenderes”, avalia.
À frente da plataforma de ensino on-line voltada para empreendedores EduK, Eduardo Lima observa uma quebra de paradigma em relação à educação à distância. “As pessoas estão percebendo que ela é tão boa quanto, e às vezes até melhor, do que o modelo tradicional. Tem empresas construindo conteúdo de muita qualidade e professores de altíssimo gabarito que estão ensinando pela internet. É uma transição natural, porque elas tornam a educação mais acessível e flexível. As edtechs tem um propósito muito transformador, mas ainda é um mercado muito jovem”, explica.
Juntando educação, saúde e tecnologia, a MedRoom vem com a proposta de fazer treinamentos na área da saúde com realidade virtual. CEO da edtech, Vinicius Gusmão percebe que o setor possui vários problemas, o que se traduz em muitas oportunidades.
“O grande desafio é escalar o projeto. A tecnologia é incrível e dá para fazer muita coisa com ela, mas não garantir o acesso democratizado a todo mundo, o que seria o ideal do ponto de vista educacional. Então temos limitações, ainda mais em um país que não tem ainda uma cultura muito forte em inovação tecnológica.”
Amure Pinho opina que um dos maiores obstáculos de se trabalhar com edtechs ainda é a falta de regulamentação. “O controle do governo em alguns requisitos ainda engessa um pouco a educação que pode ser transformada na ponta. Também temos uma formação que ainda é um pouco distante das necessidades do mercado, fazendo com o que o profissional precise se especializar mais. Outro desafio é que nós temos uma geografia e economia muito complexas e grandes, então você não consegue levar o mesmo nível de acesso à informação à todos os lugares”, analisa.
Matheus Goyas ressalta que é importante que o empreendedor tenha a humildade para reconhecer que a solução da edtech dele não vai resolver todos os problemas da educação. “Solucionar esse gargalo só vai ser possível com um trabalho em conjunto entre empreendedores, empresas, governo e educadores. A educação por si só é muito complexa”, garante. Ele também percebe que a questão geográfica é um grande limitador, tanto em questões culturais como de infraestrutura.

Jan Krutzinna concorda que a distribuição é um dos maiores desafios dos empreendedores de edtechs. “Muitas empresas são criadas com ótimas ideias mas têm dificuldades de entregar no ponto final. O sistema público também é difícil de colaborar. Tem muito potencial para crescer, mas é preciso evoluir em muitas coisas tecnológicas e conseguir recrutar talentos, o que ainda é outra dificuldade que encontramos”, revela.
Para Eduardo Lima, o maior desafio é encontrar uma proposta de valor suficientemente boa para que os clientes consumam e gerando caixa para a empresa. “São modelos que muitas edtechs ainda não conseguiram alcançar. Depois disso, é fidelizar o cliente, como em qualquer outra empresa”, opina.
Vinicius Gusmão acredita que as edtech estão no bom caminho, mas ainda falta aparecerem mais e serem criados mais incentivos para que elas deslanchem. “Talvez o Brasil ainda não tenha abraçado totalmente a onda das edtechs. O que talvez falte é um bom case de sucesso que mostre o potencial do mercado”, pondera.
Para quem trabalhar no setor, especialistas afirmam que características como ser apaixonado por transformar a vida das pessoas, focar na qualidade, ter uma conexão pessoal com a área da educação, ser empático, paciente, resiliente, ter compromisso e foco ao longo prazo e gostar de se relacionar com as pessoas, além de ter um profundo alinhamento e foco obsessivo nos clientes/estudantes.
Profissionais nas áreas de desenvolvimento de software, programação, análise de dados, front end, design, interface, marketing digital, marketing de conteúdo, mídias sociais, vendas e experiência do usuário encontrarão muitas oportunidades de trabalho nas edtechs.
Publicado por Blog Na Pratica
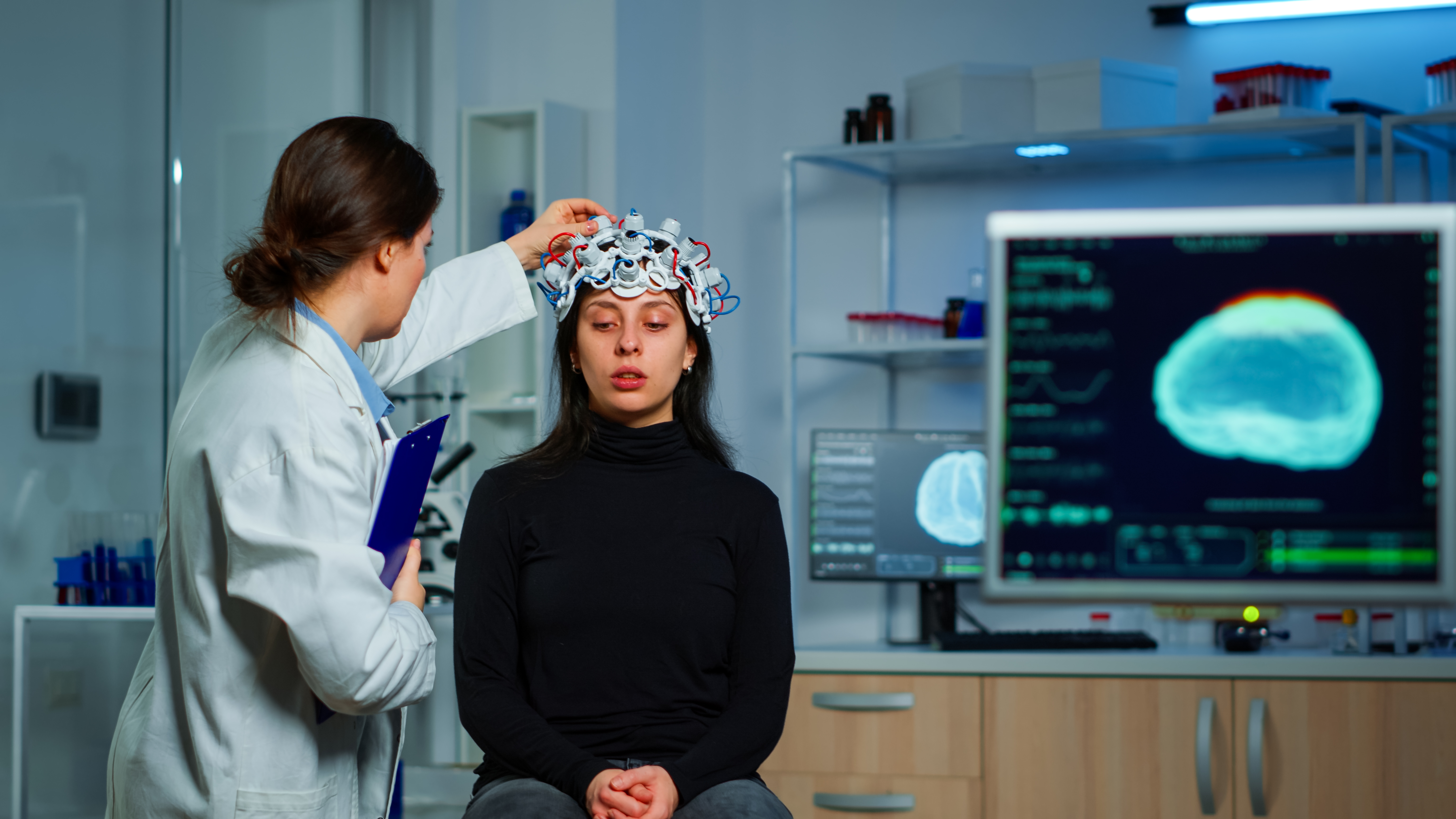
Pesquisadores desenvolveram sistema baseado em Inteligência Artificial (IA) que permitiu a uma mulher com paralisia grave falar por meio de avatar digital. A equipe implantou 253 eletrodos conectados à superfície do cérebro da paciente, interceptando os sinais cerebrais e enviando-os para análise.
Os algoritmos de IA foram treinados para reconhecer os sinais cerebrais de fala e criar sistema que decodifica palavras a partir de fonemas. A voz utilizada foi uma gravação antiga da paciente.
Além do uso na fala, os implantes cerebrais também têm sido aplicados para recuperar movimentos e sensações de pacientes tetraplégicos. A tecnologia utiliza chips para ler e interpretar a atividade dos neurônios do paciente, permitindo o controle dos braços por meio do pensamento.
Outro caso impressionante envolve um homem com paralisia que voltou a andar após um implante cerebral. O dispositivo implantado é capaz de detectar a atividade neuronal relacionada ao movimento das pernas, permitindo ao paciente recuperar sua mobilidade.
Além desses casos, os implantes cerebrais também estão sendo utilizados no tratamento de câncer no cérebro. Nessa aplicação, um dispositivo de ultrassom é combinado com a administração de remédios quimioterápicos para direcionar o tratamento aos vasos sanguíneos cerebrais, tornando o tratamento mais eficaz e direcionado.
O curso de Engenharia de Software iCEV é o primeiro e melhor do Piauí! Aqui o aluno estará apto a entrar no mercado, mas também pronto para pesquisar inovações, aliando conhecimento e prática – ele escolhe o caminho ou os caminhos que quer seguir.
O iCEV sempre traz convidados de peso e realiza verdadeiras aulas-experiências para acrescentar na formação acadêmica e na prática dos futuros engenheiros de software. Confira:
No iCEV o estudante de engenharia de software já aprende programação nos primeiros períodos e começa a desenvolver seus próprios games desde cedo! A metodologia do curso é diferenciada e aposta em eventos internos de tecnologia na qual os alunos têm que resolver problemas complexos e elaborar seus próprios produtos inovadores de tecnologia.

Eventos como Chess Challenge, Code Battle, Game Jungle e Game Jam aguçam as soft skills e hard skills dos alunos.
Conheça mais sobre cada evento:
O Campeonato de Xadrez, reuniu mais de 50 participantes em 22 equipes que desafiaram seus conhecimentos computacionais numa batalha de Inteligência Artificial.

Os participantes construíram programas de Inteligência Artificial (IA) e ensinaram as melhores decisões a serem tomadas num jogo de xadrez. Essas IAs competiram entre si.

Os estudantes foram desafiados com problemas que exigem sólidos conhecimentos em algoritmos e estruturas de dados. Além de testar os conhecimentos dos alunos, a competição era premiada e valia pontos na prova para os ganhadores.

“Game Jungle”, uma competição interna de programação de jogos.O desafio era construir um game do zero levando em consideração diversos critérios comojogabilidade; originalidade; gráficos; trilha sonora; entre outros.
Nossos alunos de Engenharia de Software participaram da Hackathon, a Maratona de Programação iCEV. A atividade foi uma competição interna dos estudantes de Tecnologia, de todos os períodos. O termo hackathon é uma junção de duas palavras em inglês: “hack”, que, nesse caso significa programar, e “marathon”, que é maratona.

O iCEV, sediou em Teresina o THE Game Jam – evento que aconteceu simultaneamente em todo o mundo. Em 48 horas, estudantes de tecnologia, desenvolvedores profissionais e apaixonados por jogos, elaboraram games com o tema “reparo”, tema escolhido pelo Global Game Jam 2020.

É assim para o engenheiro de software formado pelo iCEV, que está preparado para muitas oportunidades nacionais e internacionais. Além de empreender, o profissional pode atuar com desenvolvimento de softwares, gerenciamento de projetos, arquitetura de produtos, etc.
A tecnologia é um dos mercados que mais cresce. O salário médio de um Engenheiro de Software no Brasil é de R$9.480 por mês, +303% acima da média salarial brasileira.
Fonte: jobbydoo

Só no iCEV o estudante conta com a Fábrica de Software BITICEV. O aluno alia teoria e prática no desenvolvimento de projetos e soluções para problemas reais, voltados para o mercado de trabalho.

O iCEV investe em internacionalização, estreitando os laços com grandes players do mercado mundial de tecnologia, assim como Red Hat, Oracle e Amazon.
A Stability AI ficou famosa nos últimos meses com o Stable Diffusion, modelo de geração de imagens com inteligência artificial. Agora, ela vai partir para o campo da escrita. A empresa anunciou uma alternativa ao ChatGPT chamada StableLM, com código aberto.
O StableLM gera texto prevendo qual o próximo token, como é chamado o fragmento de palavra. A sequência começa com uma informação fornecida por um ser humano.
O funcionamento é bem parecido com o GPT-4, modelo grande de linguagem (LLM, na sigla em inglês) que serve de base para o ChatGPT.
“Modelos de linguagem formarão a espinha dorsal da nossa economia digital, e queremos que todo mundo possa opinar nesses projetos”, diz a Stability AI no blog post anunciando a novidade. “Modelos como o StableLM demonstram nosso compromisso com tecnologias de inteligência artificial transparentes, acessíveis e solidárias.”
Por enquanto, o StableLM está em fase alpha. Ele foi disponibilizado no GitHub, nos tamanhos de 3 bilhões e 7 bilhões de parâmetros. A Stability AI promete que os modelos de 15 bilhões e 65 bilhões de parâmetros serão liberados em breve.
Os parâmetros são variáveis que um modelo usa para aprender a partir dos dados de treinamento. Números menores significam que os modelos podem ser mais eficientes, podendo rodar localmente em notebooks ou smartphones.
Por outro lado, eles precisam de projetos mais elaborados para conseguir entregar bons resultados usando menos recursos.

O StableLM é mais um dos modelos grandes de linguagem a prometer desempenho próximo ao do GPT-3, da OpenAI, com número menor de parâmetros — o GPT-3 usa 175 bilhões.
Outros são o LLaMA, da Meta; o Alpaca, de Stanford; o Dolly 2.0; e o Cerebras-GPT.
Os modelos foram disponibilizados sob a licença Creative Commons BY-SA-4.0. Isso significa que projetos derivados devem dar créditos ao autor original e ser compartilhados usando a mesma licença.
Por enquanto, é possível testar uma versão do modelo de 7 bilhões de parâmetros já customizada para chatbots no Hugging Face.
Para analisar a evolução da internet, é possível dividir a história da Web em alguns estágios principais com base nas tecnologias e transformações aplicadas no período. É nesse contexto que surge o termo Web3, indicado para apontar uma nova fase entre as formas de conexão.
A Web3 é um conjunto de tecnologias que representa um novo marco durante a evolução da internet. Tem como grande premissa a descentralização da Web, reforçada por conceitos como o blockchain e a tokenização digital, indo na contramão de um cenário em que dados e plataformas ficam concentradas em Big Techs.
O termo foi criado por Gavin Wood, fundador da plataforma de blockchain Ethereum, em 2014. Vale a pena ressaltar que o conceito é muito abstrato e, em algumas situações, ainda reside no campo teórico. Mas, antes de entender o que significa essa terceira etapa, é preciso definir o que veio antes.
Esses termos foram usados para definir outras grandes evoluções no uso da internet. Não há um único ponto de partida que separa as épocas, mas pesquisadores analisam um conjunto de características semelhantes entre os períodos.
O início da World Wide Web, entre o final da década de 1980 e a década de 1990, marca esse primeiro estágio. Os sites eram principalmente estáticos, limitados a textos, hiperlinks e poucas imagens.
Por conta dessas características, a Web1 limitou a experiência dos usuários somente à leitura, com poucas opções de interação e dificuldade para obter um site próprio.
No início dos anos 2000, já era possível vivenciar a segunda evolução da internet: a Web 2.0 abria espaço para a interação entre usuários. Mensageiros instantâneos, espaços de comentários em sites e plataformas de blogs viabilizavam a criação de conteúdo próprio.
O grande salto veio com as redes sociais — as plataformas protagonizaram a experiência de ficar online e ampliaram as formas de produção (e monetização) de conteúdo. Enquanto a Web 1.0 se limitou à leitura, a etapa seguinte permitia ler e criar ao mesmo tempo.
/i725092.jpeg)
Além disso, a Web 2.0 também representou a chegada da portabilidade e dos aplicativos. Com a opção de acessar a internet em qualquer dispositivo, foi possível desenvolver plataformas versáteis e que atendessem a diferentes demandas.
O resultado é a mudança nas formas convencionais de consumo: o pedido de comida por telefone foi substituído pelo app de delivery, o táxi deu espaço para o Uber e por aí vai.
Uma das principais consequências da “Web2” foi a centralização dos dados nas Big Techs. Meta, Amazon, Google e outras gigantes da tecnologia concentraram as informações dos usuários e mantiveram o controle dos hábitos na internet entre poucos produtos.
Se a Web2 centralizou o fluxo de dados entre grandes empresas, a Web3 surgiu para descentralizar esse processo. A ideia envolve usar tecnologias de blockchain para dar poder aos usuários e permitir que eles gerenciem os próprios dados.
De forma resumida, o blockchain pode armazenar as informações sobre a propriedade de um ativo digital e disponibilizar os registros publicamente. Assim, as pessoas não dependeriam dos servidores de uma grande empresa para acessar essa informação, enquanto toda a comunidade de usuários pode manter o registro ativo, sem a participação de empresas na intermediação.
“A Web3 elimina a necessidade de intermediários porque oferece a possibilidade de realizar transações seguras diretamente entre os usuários (peer-to-peer), por meio das novas tecnologias baseadas na blockchain, como os smart contracts”, explica a CEO da consultoria especializada em Web3 Go Digital Factory, Adriana Molha. “É a era da propriedade, da descentralização e das comunidades”, complementa a executiva.
/i606725.jpeg)
Muitos dos conceitos da Web3 já são aplicados nos mercados de criptomoedas, tokens não fungíveis (NFT) e outros ativos digitais — por isso é muito difícil falar sobre um sem mencionar o outro. Esse estágio da web promete que todos poderão ler, criar e possuir alguma propriedade digital dentro da internet.
Adriana Molha reforça a importância do blockchain para essa função. “Ao mesmo tempo em que oferece a privacidade dos dados, também garante a propriedade do conteúdo produzido pelo usuário”, explica. “Em outras palavras, aquilo que é seu na Web3, é seu mesmo. Está registrado nestas redes descentralizadas chamadas Blockchains e não no servidor de alguma empresa”, prossegue.
A Web3 possui alguns pilares principais:
Aqui, a resposta fica um pouco mais complicada. Existem alguns teóricos que usam uma separação entre Web3.0 e Web3: nesse caso, a nomenclatura “3.0” representa alguns padrões de acesso a sites, enquanto a Web3 é usada para englobar todas as outras tecnologias.
Um conceito muito atribuído à Web 3.0 é o de web semântica, ou seja, uma padronização da internet que pode ser compreendida por humanos e máquinas. Isso muda a interpretação dos dados e permite que os algoritmos desenvolvam respostas e antecipem problemas.
Então, é comum que alguns pesquisadores usem o termo Web 3.0 para abordar a web semântica e Web3 para definir os processos de segurança e descentralização.
Quando o assunto é a criação de novas experiências para a internet, o metaverso é um exemplo mencionado com frequência. Apesar do espaço virtual não ser um conceito recente, ele pode ser combinado com as tecnologias da Web3 para aumentar sua popularidade.
/i642850.jpeg)
Esses dois temas se interligam quando envolvem token e ativos digitais. “O metaverso está inserido dentro do contexto da Web3 a partir do momento em que as transações nesse metaverso são feitas via tecnologia Blockchain”, reforça Adriana Molha.
“Quando é mencionado que a Web3 será uma web imersiva, podemos entender a proposta de metaverso como a interface possível para esta realização”, completa a executiva.
A forma mais prática de entender o funcionamento da Web3 ainda envolve o uso de criptomoedas. Como essas tecnologias costumam ser operadas em blockchain, já é possível compreender as etapas dessa rede.
Alguns navegadores, como o Opera e o Brave, já adaptaram a própria interface para receber recursos voltados ao Web3, como uma carteira própria de criptomoedas.
Fora do mercado financeiro, o blockchain também é utilizado para proteger assinaturas digitais, por exemplo, além de adicionar camadas de criptografia no armazenamento em nuvem. Há, inclusive, um projeto de criação de sistema de blockchain nacional para uma moeda virtual desenvolvido pelo Banco Central do Brasil, chamado Real Digital.
Por outro lado, ainda existem outros recursos que dão seus primeiros passos ou nem saíram do papel. O conceito de dApps, aplicativos criados em uma rede descentralizada e protegida por blockchain, pode ser uma resposta aos apps convencionais, mas ainda existem poucos modelos disponíveis.
Ao mesmo tempo em que procura resolver problemas gerados pela Web 2.0, o Web3 também levanta alguns questionamentos sobre o próprio jeito de funcionar.
O primeiro envolve a capacidade de processamento de dados: a tecnologia de blockchain demora para concluir uma transação e não consegue operar com tantas informações ao mesmo tempo. Por isso, servidores de Google, Amazon e outras empresas são opções mais consolidadas e com maior poder de armazenamento.
Há, ainda, a questão ambiental de todo esse processo. O blockchain depende da mineração e da presença de supercomputadores, que geram problemas a partir do consumo de energia e da necessidade do espaço físico para comportá-los.
Os riscos com a privacidade também chamam a atenção: uma carteira de criptomoedas poderia armazenar todas as informações do usuário com gastos pessoais. Nesse caso, ainda não existem métodos para ocultar alguns dados de visitantes.
(Imagem: Freepik)
Os desenvolvedores de software são divididos em três categorias principais: júnior, pleno e sênior. Cada categoria tem habilidades e responsabilidades diferentes, e é importante entender essas diferenças para saber em quais posições os desenvolvedores se encaixam melhor.
São aqueles que acabaram de entrar no mercado de trabalho ou têm pouca experiência em programação. Eles geralmente trabalham em tarefas simples, como correção de bugs ou manutenção de código existente. Eles também podem atuar em projetos pequenos e simples, mas geralmente sob a supervisão de um desenvolvedor pleno ou sênior.
São aqueles que já têm alguma experiência como desenvolvedor, mas ainda estão sempre aprendendo e aprimorando suas habilidades. Este grupo geralmente trabalha em tarefas mais complexas e podem ser responsáveis por partes específicas de um projeto, podendo também ser responsáveis por orientar e supervisionar desenvolvedores júnior, ajudando-os a crescer e maximizar suas habilidades.
São aqueles que têm muita experiência como desenvolvedores e possuem habilidades avançadas. Eles geralmente trabalham em projetos complexos e são responsáveis por tomar decisões importantes em relação ao projeto e à equipe. Eles também podem ser responsáveis por orientar e supervisionar desenvolvedores plenos e júnior, ajudando-os a crescer e se desenvolver.
Cada categoria de desenvolvedor tem suas próprias responsabilidades e habilidades, e cada uma é importante para o sucesso de um projeto. Desenvolvedores júnior fornecem suporte básico, enquanto desenvolvedores plenos e sêniors fornecem suporte mais avançado e tomam decisões importantes.
É importante ter em mente que essas classificações são baseadas na experiência e habilidade dos desenvolvedores e não são uma medida exata da capacidade de um desenvolvedor, nem mesmo no tempo de experiência. Alguns desenvolvedores júniores podem ser muito talentosos e capazes, enquanto alguns desenvolvedores sêniors podem não ser tão habilidosos.

(Imagem: Freepik)
Há algumas habilidades e características que podem ajudar um desenvolvedor júnior a se tornar um desenvolvedor pleno:
👉Conhecimento técnico: Um desenvolvedor pleno deve ter um bom conhecimento das ferramentas, linguagens e técnicas utilizadas em seu trabalho. Conforme vai ganhando experiência, deve estar sempre buscando aprender novas tecnologias e aprimorar as já conhecidas.
👉Comunicação eficaz: Um desenvolvedor pleno deve ser capaz de se comunicar eficazmente tanto com os membros da equipe quanto com os clientes ou usuários finais. Isso inclui a capacidade de explicar complexidades técnicas de forma simples e clara.
👉Habilidade de resolução de problemas: Um desenvolvedor pleno deve ser capaz de resolver problemas técnicos e encontrar soluções para problemas com pouca ou nenhuma orientação.
👉Habilidade de trabalhar em equipe: Um desenvolvedor pleno deve ser capaz de trabalhar em equipe e colaborar com outros desenvolvedores e profissionais de outras áreas.
👉Autonomia: Um desenvolvedor pleno deve ser capaz de tomar decisões e trabalhar de forma autônoma. Isso inclui a capacidade de priorizar e gerenciar suas tarefas, bem como a capacidade de lidar com mudanças e adaptar-se a novos desafios.
Essas habilidades e características não são exigidas de forma simultânea, e a evolução de um desenvolvedor júnior para um desenvolvedor pleno pode levar algum tempo. No entanto, trabalhando nessas áreas, é possível desenvolver as habilidades necessárias para se tornar um desenvolvedor pleno e eficaz.
Os salários para desenvolvedores de software variam amplamente no Brasil, dependendo de fatores como localização, tipo de empresa, habilidades e experiência. No entanto, é possível dar uma ideia geral das faixas salariais para cada categoria de desenvolvedor:

(Imagem: Freepik)
Desenvolvedor júnior: pode ganhar entre R$ 2.500 e R$ 4.500 por mês, dependendo da localização e do tipo de empresa. Isso pode aumentar para R$ 5.000 a R$ 7.000 por mês para desenvolvedores com habilidades mais avançadas e/ou experiência anterior.
Desenvolvedor pleno: pode ganhar entre R$ 5.000 e R$ 8.000 por mês, dependendo da localização e do tipo de empresa. Isso pode aumentar para R$ 8.000 a R$ 12.000 por mês para desenvolvedores com habilidades mais avançadas e/ou experiência anterior.
Desenvolvedor sênior: pode ganhar entre R$ 8.000 e R$ 12.000 por mês, dependendo da localização e do tipo de empresa. Isso pode aumentar para R$ 12.000 a R$ 15.000 por mês para desenvolvedores com habilidades mais avançadas e/ou experiência anterior.
Existem algumas áreas de TI que geralmente oferecem salários mais elevados para desenvolvedores juniores. Essas áreas incluem:
Desenvolvimento de jogos é uma área em crescimento e pode oferecer salários atraentes. Isso pode incluir desenvolvimento de jogos para dispositivos móveis, consoles e computadores pessoais.
Desenvolvimento de inteligência artificial (IA) e aprendizado de máquina (ML) está em alta demanda e podem oferecer salários mais elevados para desenvolvedores juniores com habilidades em IA e ML.
Segurança da informação é uma área crítica e pode oferecer salários mais elevados para desenvolvedores juniores com habilidades em segurança de rede e criptografia.
O desenvolvimento de blockchain também está em crescimento e requer pouca experiência para início na carreira.
Desenvolvimento de aplicativos móveis tem alto acoplamento para desenvolvedores juniores e é uma excelente porta de entrada para uma carreira promissora.

(Imagem: Freepik)
Neste contexto, é importante frisar que a área de TI que engloba esses níveis profissionais está em franca expansão. Pode-se afirmar isso devido a vários fatores, dos quais destacamos:
Crescimento do setor: A tecnologia está se tornando cada vez mais importante em quase todos os setores, e isso está impulsionando o crescimento do setor de TI. Isso significa que há uma grande demanda por profissionais de TI qualificados, o que aumenta as oportunidades de carreira e salários.
Inovação contínua: A tecnologia está sempre evoluindo e há sempre novas tendências e inovações emergentes.
Ampla variedade de carreiras, desde desenvolvimento de software e segurança da informação até gerenciamento de projetos e gerenciamento de TI.
Salários atraentes: Profissionais de TI geralmente ganham salários mais elevados do que profissionais em outras áreas, especialmente para aqueles com habilidades e experiência avançadas.
Oportunidades globais: A tecnologia é utilizada em todo o mundo, o que significa que as oportunidades de carreira em TI são globais. Isso pode incluir trabalhar para empresas multinacionais ou viajar para trabalhar em projetos em outros países.
Oportunidade de trabalhar remotamente: A pandemia aumentou a necessidade de trabalhar remotamente e muitas empresas estão adotando essa modalidade como uma forma de trabalhar. Isso oferece aos profissionais de TI a flexibilidade de trabalhar de qualquer lugar, o que pode ser uma grande vantagem.
A própria construção desse artigo é um exemplo de como a revolução digital é imparável. Este artigo foi escrito em conjunto com a ajuda de ChatGPT, um modelo de linguagem de grande porte treinado pela OpenAI. O processo funcionou da seguinte maneira:
O usuário forneceu um conjunto de perguntas ou tópicos para o qual desejava obter informações.
O modelo de linguagem ChatGPT foi utilizado para gerar uma resposta baseada em seu conhecimento prévio e sua capacidade de compreender e produzir texto natural.

O modelo de linguagem ChatGPT forneceu um conjunto de respostas, que foram revisadas, validadas e editadas pelo usuário para garantir precisão e clareza.
O usuário pode continuar perguntando e o modelo de linguagem ChatGPT continuaria gerando respostas para continuar o artigo.
É importante notar que, embora o modelo de linguagem ChatGPT seja capaz de gerar respostas precisas e informativas, ele não possui opiniões ou sentimentos próprios e pode não estar completamente atualizado com as informações mais recentes. Portanto, é importante verificar e editar as informações geradas pelo modelo antes de usá-las. A revolução não para.

Engenharia de Software é, por definição, a aplicação de técnicas, conhecimentos e ferramentas à construção de software de qualidade. A função do engenheiro de software é produzir aplicações que atendam às necessidades dos clientes dentro do prazo e orçamento disponíveis.
Software é construído através do processo de programação. Embora o processo de desenvolvimento envolva outros passos anteriores à codificação, o software não fica pronto sem programação.

(Imagem: freepik)
Programação é o processo de criar e descrever um conjunto de instruções que informem a um computador o que fazer para resolver um dado problema. Para programar, é necessário entender a lógica básica de programação (algoritmos) e alguma linguagem de programação que possa ser “entendida” pelo computador.
Diante da importância da programação no desenvolvimento de software, cursos e discussões na área tendem a focar fortemente em desenvolver habilidades técnicas voltadas para essa atividade. De fato, basta olhar a grade de qualquer curso de engenharia de software ou computação e veremos disciplinas voltadas para programação em praticamente todos os blocos.
Com essa informação, parece que todo engenheiro de software precisa ser, acima de tudo, um programador. Mas será mesmo verdade?
Programação é uma habilidade complexa. É também uma atividade complexa e longa.
Programar envolve criar algoritmos. A base para a criação de qualquer programa é a definição da sequência de instruções que serão realizadas para resolver o problema do cliente. Esse conjunto de instruções é conhecido como algoritmo.
Criar algoritmos exige conhecimento das estruturas de comando e de lógica matemática, bem como a capacidade de visualizar e organizar a solução para problemas.
Além disso, programar exige o domínio de uma linguagem de programação. Linguagens de Programação são sistemas de notação que podem ser compreendidos pelo computador. Computadores não entendem o que chamamos de linguagens naturais (as que falamos no dia a dia, como o português). Por isso, é necessária uma linguagem que possa ser entendida tanto pelo programador quanto pelo computador. Diversas dessas linguagens existem no mercado, é cada software é desenvolvida em uma linguagem.

(Imagem: freepik)
Por esses motivos, nem todos desejam dedicar tempo ou esforço para a atividade de programação. Algumas pessoas não se interessam por aprender as habilidades necessárias. Outras, mesmo sabendo programar, não demonstram interesse pelo dia a dia da atividade.
Ainda assim, várias dessas pessoas se interessam pelo poder de inovação e solução de problemas que a área de engenharia de software pode trazer. Existem espaços para aqueles que não desejam ou não conseguem programar dentro do universo da produção de software.
Desenvolver software envolve programar, mas essa não é a única atividade envolvida na Engenharia de Software. Entender as necessidades, projetar as interfaces, controlar as equipes, acompanhar os usuários e muitas outras atividades são necessárias para a criação e manutenção de softwares em qualquer ambiente.
Essas atividades são melhor exercidas por pessoas com expertise na área de Engenharia de Software, mas não exigem habilidades de programação propriamente ditas. São atividades voltadas para o gerenciamento da equipe, para o contato com o cliente ou para a operação cotidiana do software.
Seguem alguns dos principais trabalhos que um engenheiro de software pode fazer sem precisar escrever código.
Geralmente o cliente de uma equipe de desenvolvimento de software não é um profissional da área. Clientes são, em última análise, usuários finais. Assim, eles não entendem o linguajar e os métodos envolvidos no desenvolvimento de software. Isso pode dificultar a comunicação entre as partes envolvidas.
Entra em cena o Product Owner, profissional responsável pela comunicação entre a equipe e o cliente. Mais que a comunicação, o P.O. funciona como um representante do cliente junto à equipe.

(Imagem: freepik)
A função do Product Owner é garantir que o software atenda as necessidades dos clientes. O P.O. precisa entender não apenas o que o cliente afirma querer, mas o que ele efetivamente precisa para resolver seus problemas. Um bom P.O. consegue visualizar o produto de forma estratégica para direcionar o trabalho da equipe.
O trabalho cotidiano do Product Owner consiste em especificaras funcionalidades do software a serem desenvolvidas, tirar dúvidas da equipe sobre as necessidades do cliente, atribuir prioridades diferentes para cada funcionalidade e avaliar as funcionalidades entregues.
O desenvolvimento de um software se encaixa perfeitamente na definição tradicional de um projeto (“Um esforço finito com o objetivo de produzir um produto ou serviço novo”). Por isso está sujeito às mesmas restrições que qualquer projeto: Prazo, custo e escopo. Está, também, sujeito a riscos e a restrições de pessoal. Alguém precisa controlar essas restrições e riscos.
Essa função cabe ao Gerente de Projetos. Ele é o responsável final pelo sucesso do esforço de desenvolvimento. Cabe ao gerente planejar e estimar o projeto, bem como se preparar para riscos e controlar e facilitar o trabalho da equipe.
As atividades do dia a dia de um gerente de projeto são estimar o prazo e o custo do processo de desenvolvimento, estabelecer o cronograma de desenvolvimento, montar a equipe do projeto, identificar e criar planos de contingência para possíveis riscos e controlar e liderar a equipe de software.
Por controlar e liderar a equipe de software entende-se acompanhar o trabalho, garantindo que o mesmo cumpra o cronograma estabelecido, e ajudar a equipe a manter o ritmo, tanto motivando a equipe como removendo eventuais obstáculos que a equipe encontre, mas não tenha autoridade para remover.
O nível de autonomia e de poder que gerentes de projeto possuem variam entre organizações, mas de forma geral eles operam como líderes e chefes de equipes. Bons gerentes de projeto devem ter capacidades de liderança, negociação e resolução de conflitos.,
Um produto de software não existe no vácuo. Ele tem a função de resolver um problema enquanto é usado pelo usuário, bem como de existir no ecossistema de T.I. da empresa. Em resumo, um sistema oferece um conjunto de experiências ao usuário.
Essa lógica não se aplica somente a software. Qualquer produto existe, ao fim e ao cabo, para oferecer um conjunto de experiências ao usuário. Mesmo produtos simples, como uma roupa, existem em função do que eles oferecem quando usados.
Produtos podem, e devem, ser projetados a partir de suas funcionalidades, mas podem, também, ser projetados com a experiência do usuário em mente. Todo o produto pode ser pensado de forma a otimizar a forma como o usuário se sente e como ele interage com o produto.

(Imagem: freepik)
A título de exemplo, olhemos o caso do Iphone. Smartphones já existiam antes dele, como o Blackberry ou o Sidekick. O que a Apple fez com o primeiro Iphone foi visualizar uma experiência mais agradável, com o touchscreen, a aparência mais bonita e a tela com cores mais vivas. Perceba-se que as funções básicas de um smartphone já eram atendidas pelos antecessores, mas a experiência oferecida pelo Iphone era diferente. Por isso, o produto revolucionou o mercado.
Essa mesma lógica se aplica ao desenvolvimento de software. Produtos de software podem ser pensados com foco na experiência que o usuário final terá ao utilizá-lo. Esse é o trabalho do User Experience Designer (Designer de Experiência do Usuário, em uma tradução livre), ou UX Designer.
Bons UX Designers deve ter a capacidade de se colocar no lugar do usuário, foco na satisfação e boa comunicação. Precisam também ter a capacidade de enxergar o produto como um todo. Conhecimento de técnicas de design de soluções também pode ser um diferencial.
É comum confundir UX Design e UI Design. Enquanto o UX Designer foca na experiência como um todo, o UI Designer foca especificamente na maneira como o usuário vai interagir com o sistema. O termo UI significa User Interface, ou Interface de Usuário.
O UI Designer tem um trabalho mais técnico, projetando e desenhando as interfaces que o usuário visualizará ao lidar com um sistema. Ele vai se preocupar com telas, ergonomia, organização da informação, cores e coisas similares.
O trabalho do designer de interfaces exige capacidade de organização visual e capacidade de entender seus usuários. O bom UI Designer consegue entender a diferente facilidade ou dificuldade de cada grupo de usuários com cada tipo de interface.
Vale ressaltar que muitas equipes de software colocam o trabalho de UI Designer sob a mesma tutela do UX Designer, para minimizar a quantidade de membros. Embora isso seja comum, não significa que sejam a mesma coisa. UX Designer foca na experiência do usuário e UI Designer foca exclusivamente nas telas.
O projeto de software é o processo de tomar decisões acerca de como o software será feito. Geralmente pode ser entendido em vários níveis de detalhamento diferente. Desde o projeto extremamente detalhado descrevendo estruturas de dados, algoritmos ou classes, até o mais amplo, que descreve tecnologias e partes básicas do sistema.
Esse último tipo de projeto, considerado um projeto de alto nível (pois mais distante da implementação propriamente dita), é conhecido como arquitetura do software. A arquitetura do software vai descrever a pilha tecnológica usada, quais as partes do sistema e como essas partes falarão entre si.
Um projeto de arquitetura pode, por exemplo, especificar em quantos componentes o sistema será dividido, em que linguagem cada componente será implementado, quais frameworks de desenvolvimento serão utilizados, onde e como serão hospedados os componentes e como cada componente se comunicará com os outros.

(Foto: Denise Nascimento)
Para citar um exemplo mais prático: Uma arquitetura bastante comum hoje em dia é criar o sistema com três componentes. Um banco de dados em algum sistema gerenciado de bancos de dados moderno (sistema de armazenamento de dados), um “backend” em Java utilizando framework Springboot e hospedado através de um servidor de aplicações Wildfly e um “frontend” em TypeScript, utilizando plataforma Angular e hospedado em um servidor Node.js. O frontend se comunica com o backend via HTTP resdtfull (tecnologia para comunicação simples via WEB) e o backend se comunica com o sistema gerenciador de bancos de dados utilizando JDBC (tecnologia própria para a comunicação entre aplicações Java e sistemas gerenciadores de bancos de dados).
O trabalho de criar, manter e comunicar esses projetos de arquitetura é responsabilidade do arquiteto de software. Esse profissional se dedica a, com o auxílio da equipe, decidir quais serão os componentes, quais funcionalidades serão implementadas em cada componente e como cada componente será implementado.
Bons arquitetos de software devem conhecer linguagens de modelagem, entender as tecnologias e tendências do mercado, ter noção básica de vantagens e desvantagens de tecnologias e linguagens de programação, além de ter capacidade de resolução de problemas, organização e priorização.
Um clichê comum sobre a tecnologia da informação é que os dados serão o próximo petróleo. A frase significa que as novas fortunas surgirão de empresas que manipulam e extraem informação. Embora clichês tendam a ser frases sem sentido, esse tem mais que um pé na realidade.
Parte importante das necessidades dos clientes atuais é entender os dados é transformá-los em informações. Dados são fatos individuais enquanto informação é a organização e interpretação desses fatos.
Um dos profissionais responsáveis por interpretar dados e extrair informações e conhecimento deles é o analista de informação. Analistas de informação utilizam ferramentas de dados e de análise para interpretar os dados de diversas fontes e encontrar padrões e narrativas a partir das informações.
É o analista de informação que vai utilizar os dados para entender o comportamento de clientes, prever tendências a auxiliar na tomada de decisões.
Para realizar o trabalho, um profissional da área precisa ter capacidade de comunicação e de previsão, além de conhecimento razoável de estatística e, preferencialmente, álgebra linear.
Se analistas de informação e cientistas de dados vão acessar dados de diversas fontes diferentes para executar suas funções, alguém precisa organizar esses dados. Essa função pertence ao engenheiro de dados.
Engenheiros de Dados tem a responsabilidade de gerenciar fontes de dados tanto estruturadas (como bancos de dados) como não estruturadas (como textos ou bancos de imagens) e organizar ferramentas que permitam cientistas ou analistas trabalhar com esses dados.
Um engenheiro de dados deve ter conhecimento de bancos de dados e outras arquiteturas de dados. Ele precisa, também, conhecer ferramentas de big data e de conversão de dados. Além disso, é interessante que o engenheiro apresente habilidades de colaboração e criatividade. Por fim, conhecimento básico das áreas de ciência de dados ou análise de informação, conforme a área em que se trabalha, pode ajudar.
Sistemas gerenciadores de bancos de dados são a ferramenta número um para armazenamento de dados no mercado moderno de T.I. Esses sistemas são ferramentas que permitem, com relativa facilidade, armazenar, recuperar e manipular dados de forma concorrente e segura.
As estruturas de dados armazenadas dentro de um banco de dados precisam ser criadas, otimizadas e mantidas. Criadas para que se possam armazenar os dados dentro delas, otimizadas para garantir que a recuperação dos dados se dê da forma mais eficiente possível e mantidas para garantir que as estruturas de dados atendam às eventuais mudanças do software.
Os administradores de bancos de dados (e seus auxiliares, os operadores de bancos de dados) são os responsáveis por essas tarefas. Eles vão operar e manter os bancos de dados da empresa, bem como tomar decisões sobre a organização das estruturas de dados.
Em muitas organizações o administrador de bancos de dados acumula as funções do engenheiro de dados ou até do analista de informações, mas essas são funções tecnicamente diferentes.

(Imagem: freepik)
Dado o tema desse artigo, é preciso ressaltar que essa não é uma função 100% livre de codificação. É comum se usar linguagens de consultas, como SQL, para realizar as funções do administrador. Decidimos incluir essa função no artigo por dois motivos. Primeiro pois as ferramentas modernas de administração de bancos de dados permitem realizar quase todas as operações sem necessidade de codificação e segundo porque linguagens de consulta são formas bastante simplificadas e domínio bastante restrito de linguagens de programação.
Além de conhecimento de bancos de dados e das ferramentas de bancos dados, um bom administrado de bancos dados precisa ter capacidade de organização e visão analítica dos problemas.
Uma vez desenvolvido o software, ele vai ser colocado para funcionar (ou em produção, como se diz no jargão de T.I.) e ser operado no dia a dia pelos usuários finais. Esses usuários podem vir a precisa de ajudas ou pequenas operações administrativas no sistema, como correção de erros ou cadastro de usuários. Além disso, operações administrativas de menor porte, como backups e restauração de sistemas podem ser necessárias.
Os responsáveis por todas essas operações é o analista de suporte e sua equipe. Esse é um profissional de perfil técnico, que tomará as decisões referentes ao suporte ao usuário, as regras e padrões desse suporte, o hardware e os softwares auxiliares instalados na organização e a forma como se farão as operações administrativas.
Vale ressaltar que o analista de suporte não é, necessariamente, a pessoa que vai realizar as operações de suporte ou administração, mas o responsável por discutir e implementar regras e políticas para essas operações. Em geral., ele terá em sua equipe pessoas responsáveis pela implementação manual ou pela automatização dessas tarefas.
Por ser uma das funções com maior número de atividades, é também uma das que requer maior número de habilidades técnicas. Conhecimento de softwares e hardwares existentes no mercado, conhecimento dos softwares a que se dá suporte e de ferramentas e metodologias de suporte são essenciais para esse profissional. Além disso, ele deve ser focado no cliente, ter boa capacidade de comunicação e de gerenciar relacionamentos, bem como resposta rápida aos problemas.
Como se pode ver, existem diversas funções que podem ser exercidas por engenheiros de software sem necessidade de programação. Essas funções permitem a engenheiros de software continuar participando do processo inovativo sem necessidade de se dedicar ao trabalho de codificação.
Vale ressaltar que, embora esses trabalhos normalmente não exijam programação propriamente dita, um conhecimento básico de lógica de programação e das tecnologias de programação podem auxiliar na comunicação com a equipe e na capacidade de avaliar o software.

Análise de dados, machine learning, inteligências artificiais e computação quântica, todas essas tecnologias têm como base o inglês, tanto nas linguagens de programação, como na comunicação entre os profissionais de TI de todo o mundo.
Dominar bem o inglês, principalmente o técnico, é uma exigência imprescindível para os bons profissionais da área de tecnologia.

A disciplina estará presente em todos os períodos do curso de Engenharia de Software
O iCEV quer formar os melhores profissionais de Tecnologia do Piauí, por isso o curso de Engenharia de Software agora oferta para seus estudantes a disciplina de “English for Technology”, que estará presente em todos os períodos, desde o primeiro período.

Professor Ney Rubens
Quem vai comandar a disciplina é o professor Ney Rubens, que é mestre em Educação pela Universidad del Atlántico (Barcelona, Espanha), é especialista em inglês acadêmico com experiência na área do ensino de idiomas há mais de 20 anos, além da experiência prática após anos morando no exterior.
“Inglês é a porta do mundo globalizado para os profissionais de tecnologia. Saber Inglês escancara portas para empresas de todo o mundo. Tudo isso aliado ao conteúdo dinâmico e moderno da faculdade”, afirma Dimmy Magalhães, coordenador do curso de Engenharia de Software do iCEV.
Com isso, o iCEV está preparando os futuros profissionais para oportunidades internacionais, já que muitas empresas globais de tecnologia procuram profissionais de qualquer lugar do mundo para atuar de forma remota. Assim, o domínio da língua inglesa se torna essencial.

Aqui estão alguns termos e siglas em inglês que todo profissional de TI deve conhecer. Confira:
Bit
Bit é a menor unidade de informação que pode ser armazenada ou transmitida por um dispositivo.
Internet of Things – IoT
Internet of Things ou Internet das Coisas é um termo utilizado para a conectividade de diversos equipamentos à internet, como geladeiras, tênis, lâmpadas, produtos que até pouco tempo não utilizavam a internet.
Com a expansão do 5G, é esperado que a internet das coisas se expanda no Brasil e no mundo.
Information Technology – IT
IT é o acrônimo em inglês para a TI (Tecnologia da Informação), termo que abrange todas as soluções tecnológicas para facilitar o acesso e o gerenciamento de informações.
Bug
A palavra bug tem como tradução inseto, mas também é empregada na área de tecnologia para situações em que o software ou hardware não funciona conforme esperado. O termo entrou em uso na área de TI na década de 40, quando um computador teria parado de funcionar pela presença de um inseto no equipamento.
Hypertext Markup Language – HTML
É uma linguagem utilizada para a construção e desenvolvimento de websites, por meio de textos que serão interpretados pelos navegadores. Podemos traduzir a sigla HTML como Linguagem de Marcação de Hipertexto.
Cascading Style Sheets – CSS
Cascading Style Sheets, ou Folhas de Estilo em Cascatas, é um mecanismo utilizado para personalizar um documento web por meio da mudança de estilo, cores e fontes, por exemplo. O CSS trabalha em conjunto com o HTML na construção do layout de um website.
Business Intelligence – BI
A sigla BI significa Business Intelligence, ou “inteligência de negócios”, em português. É uma área em grande expansão no Brasil e no mundo, abrangendo todo processo de coleta, análise e gerenciamento de informações que darão suporte à tomada de decisões estratégicas.
Cloud Computing
Cloud Computing ou computação em nuvem abrange recursos tecnológicos que não estão presentes no computador, mas totalmente on-line. Com a expansão da internet e o aumento da velocidade de conexão, surgiram muitos serviços em nuvem que oferecem armazenamento de dados on-line, como o Google Photos, por exemplo.
Uniform Resource Locator – URL
Uniform Resource Locator ou localizador uniforme de recursos é o termo referente ao endereço no qual se encontra um arquivo, website ou dispositivo periférico. Na internet é utilizado como sinônimo de link.
Structured Query Language – SQL
Pode ser traduzido como linguagem de consulta estruturada. Na área de TI, query é utilizado para toda consulta ou pedido de informação realizado em um banco de dados através de comandos específicos.
Domain Name System – DNS
Domains Name System, ou Sistema de Nomes de Domínios, em português, é o sistema que converte sites (exemplo: www.lfidiomas.com.br) em endereços de IPs para serem lidos por máquinas (por exemplo, 192.1.2.44.42).
Cache
Cache é a área de armazenamento de dados e processos, visando economizar tempo e uso de hardware. Muitos navegadores costumam utilizar a memória cache para guardar dados dos sites mais acessados para posteriormente abri-los com maior rapidez.
Database
Termo em inglês para banco de dados, o conjunto de arquivos que guardam informações de forma estruturada.
Malware
Esse termo vem da junção de malicious (malicioso) com software. É todo programa criado para causar danos a dispositivos, roubar dados e prejudicar os usuários. Os vírus são os exemplos mais conhecidos de malware.
Spyware
Spyware é um malware criado para rastrear informações do usuário sem que ele saiba. Muitas vezes são utilizados por parceiros abusivos, governos antidemocráticos ou para apresentar propagandas segmentadas.
Ransomware
Ransomwares são malwares que funcionam como um programa de extorsão, exigindo algo do usuário (geralmente dinheiro) em troca da integridade dos dados no dispositivo. O backup também é utilizado na prevenção de ataques de ransomwares
Foram muitos eventos marcantes pra galera de Engenharia de Software. Por isso, preparamos uma retrospectiva para relembrar o quanto 2022 foi incrível! Confira:

(Foto: Denise Nascimento)
Logo no primeiro dia de aula da disciplina de Empreendedorismo, ministrada pelo prof. Thiago Rodrigo, os estudantes de Engenharia de Software visitaram o Sebrae Lab – ambiente de networking e inovação do Sebrae. Além disso, todo o material e metodologia utilizadas na disciplina são do Sebrae. O papo sobre inovação com o empresário e mentor Diego Silva foi bem dinâmico e interativo.

(Foto: Denise Nascimento)
O Startup Day foi só sucesso. Estivemos no evento do Sebrae com professores, colaboradores e alunos fazendo networking, participando das discussões e espalhando a mensagem do iCEV, claro! Alguns dos nossos professores de Administração e Engenharia de Software também palestraram no evento.
Além de ser um encontro de empresas de tecnologia e inovação, o Startup Day foi um momento de formação e troca de experiências para quem se aventura ou quer se aventurar no mundo das startups.

(Foto: Denise Nascimento)
A maratona aqui é diferenciada! No dia 4 de julho rolou a Hackathon iCEV, maratona de programação do curso de Engenharia de Software. Durante toda a tarde as equipes tinham 10 desafios bem difíceis para resolver.
Quem levou a melhor foi a equipe “Mendigos do ponto”, que ganhou livros, pontos em avaliações do semestre e outros mimos! Fizeram bonito demais.

(Foto: Denise Nascimento)
Esse é um espaço com máquinas modernas pra galera da Tecnologia colocar os conhecimentos em prática. O laboratório é utilizado tanto para a graduação como para a pós-graduação.

(Foto: Denise Nascimento)
No Observatório das Eleições iCEV, os estudantes puderam visitar o Depósito Central das Urnas do Tribunal Regional Eleitoral do Piauí – TRE. A visita foi acompanhada pelo professor de Engenharia de Software do iCEV e servidor do TRE, Anderson Cavalcanti.
O intuito foi conhecer, na prática, como funciona a organização das eleições e a segurança das urnas para uma votação.

(Foto: Denise Nascimento)
Troca de experiência com quem sabe muito. A convite do prof. Dimmy Magalhães, a Tech Lead da Dasa, Thainá Mariani, apresentou aos nossos estudantes de Engenharia uma palestra sobre boa qualidade de códigos e o futuro promissor no mercado de software.

(Foto: Denise Nascimento)
O projeto é um grupo de pesquisa de Direito e Engenharia de Software, liderado pelos coordenadores dos cursos Horácio Neiva e Dimmy Magalhães, respectivamente, e pelo coordenador de pesquisa e extensão, Euzébio Pereira.
São 25 estudantes no grupo de estudos. Essa interdisciplinaridade entre os cursos permite uma maior compreensão de todo o processo, pois envolve as análises jurídicas e o tratamento de dados eleitorais.
O intuito foi realizar palestras, debates, estudos, pesquisas, avaliações e produção de conteúdos relacionados às Eleições de 2022, bem como ao papel e à estrutura da Justiça Eleitoral nesse processo.

(Foto: Denise Nascimento)
O Chess Challenge foi um sucesso! O Campeonato de Xadrez reuniu mais de 50 participantes em 22 equipes que desafiaram seus conhecimentos computacionais numa batalha de Inteligência Artificial.Os participantes construíram programas de Inteligência Artificial (IA) e ensinaram as melhores decisões a serem tomadas num jogo de xadrez. Essas IAs competiram entre si. O campeonato premiou o 1º e o 2º lugar com R$ 1.000 e R$ 500, respectivamente.

Os estudantes de Engenharia de Software viveram uma experiência no estilo do programa mundialmente conhecido “Shark Tank”. A atividade, comandada pelo professor Artur Veloso, envolveu os alunos do 1º e do 2º período, pela disciplina de Cenários II, e do 7º, pela disciplina de Gerência.
Durante todo o período de 2022.2, os alunos foram envolvidos com a proposta do professor que culminou com a atividade final e teve convidados de renome na tecnologia e gestores de startups piauienses.
A prática foi dividida na criação das startups, na gestão delas e na apresentação das ideias. Na última fase, os convidados José Artur e André Junhson fizeram o papel de “tubarões”. Eles avaliaram tanto as startups como a gerência de cada uma delas.
2022 foi um ano transformador para inovação tecnológica e transformação digital. A tendência continuará à medida que o ritmo de desenvolvimento de tecnologias emergentes potencialmente disruptivas aumenta exponencialmente a cada ano. Surge a pergunta: o que está por vir para a tecnologia para aprendermos e experimentarmos em 2023?

Embora existam muitos tópicos de tecnologia impactantes, como Internet das Coisas, 5G, Espaço, Genômica, Biologia Sintética, Automação, Realidade Aumentada e outros, existem quatro áreas de tecnologia para manter um olhar atento neste próximo ano, pois elas têm promessas e capacidades de curto prazo para transformar vidas. Eles incluem: 1) Open AI, 2) Inteligência Artificial, 3) Computação Cognitiva e 4) Computação Quântica.
Desde que o computador HAL2000 e o produtor Stanley Kubrick forneceram um vislumbre da capacidade independente (embora nefasta) da IA de pensar., esperamos ansiosamente pelo surgimento da inteligência artificial. Estamos agora próximos da IA muito além da ficção. Os elementos que compõem a IA consistem em aprendizado de máquina e processamento de linguagem natural e agora fazem parte do dia a dia de nossas vidas. Hoje, a IA pode entender, diagnosticar e resolver problemas – em alguns casos sem ser especificamente programada.

O foco e os desafios da inteligência artificial são claros. Os sistemas de IA buscam replicar características humanas e capacidades computacionais em uma máquina, além de superar as limitações e a velocidade humanas. Já está acontecendo. Sinapses artificiais que imitam o cérebro humano provavelmente irão direcionar a próxima geração de computação. Os componentes podem diferir, podem ser analógicos ou digitais e podem ser baseados em transistores, produtos químicos, biológicos ou possivelmente componentes quânticos.
Computadores com IA foram projetados predominantemente para atividades de automação que incluem emulação de memória, reconhecimento de fala, aprendizado, planejamento e resolução de problemas. As tecnologias de IA podem fornecer uma tomada de decisão mais eficiente ao priorizar e agir sobre os dados, especialmente em redes maiores com muitos usuários e variáveis. Num futuro muito próximo, a IA vai mudar a forma como fazemos negócios, como planejamos e como projetamos. Você pode vê-lo agora. A IA já é um catalisador para impulsionar mudanças fundamentais em muitos setores, como atendimento ao cliente, marketing, bancos, saúde, contabilidade empresarial, segurança pública, varejo, educação e transporte público.
Recentemente, uma caixa de bate-papo chamada OpenGPT chamou a atenção para o potencial da IA e suas correlações semelhantes às humanas, especialmente ao se expressar em análises escritas. O DALL-E , outro aplicativo OpenAI, mostrou a capacidade de criar imagens a partir de instruções básicas. A noção de IA escrevendo seu próprio código, criando suas próprias linguagens é intrigante e potencialmente alarmante.

Outra área muito empolgante de potencial avanço para a IA é a interface humano/computador que ampliará a capacidade e a memória do cérebro humano. A ciência já está fazendo grandes avanços na interface cérebro/computador. Isso pode incluir chips neuromórficos e mapeamento cerebral. As interfaces cérebro-computador são formadas por meio de dispositivos emergentes que possuem sensores implantáveis que registram sinais elétricos no cérebro e usam esses sinais para acionar dispositivos externos.
Foi demonstrado que uma interface cérebro-computador é capaz de ler pensamentos. Isso é feito quando uma placa de eletrodo chamada ECOG é colocada em contato direto com a superfície do cérebro para medir a atividade elétrica.
Uma publicação da Frontiers in Science envolvendo a colaboração de acadêmicos, institutos e cientistas resumiu a promessa da interface humano-computador. Eles concluíram que “podemos imaginar as possibilidades do que pode vir a seguir com a interface cérebro-máquina humana. Um sistema B/CI humano mediado por nanorrobótica neural poderia capacitar os indivíduos com acesso instantâneo a todo o conhecimento humano cumulativo disponível na nuvem e melhorar significativamente as capacidades e inteligência de aprendizado humano. Além disso, pode fazer a transição de realidades virtuais e aumentadas totalmente imersivas para níveis sem precedentes, permitindo experiências mais significativas e uma expressão mais completa/rica para e entre os usuários.

E com o surgimento de todas as tecnologias vem a fusão de como elas podem funcionar juntas. A inteligência artificial é, sem dúvida, um dos principais catalisadores envolvidos no aprimoramento de capacidades, especialmente na computação.
O mundo da computação testemunhou avanços sísmicos desde a invenção da calculadora eletrônica na década de 1960. Os últimos anos no processamento de informações foram especialmente transformadores em nosso mundo hiperconectado. O futurista Ray Kurzweil disse que a humanidade será capaz de “expandir o escopo de nossa inteligência um bilhão de vezes” e que “o poder da computação dobra, em média, a cada dois anos. Descobertas recentes em física, nanotecnologias e nos trouxeram para uma realidade de computação cognitiva que não poderíamos ter imaginado uma década atrás.
A computação biológica é a ciência avançada de usar produtos biológicos para executar ações que tradicionalmente seriam feitas usando componentes como fio de cobre e fibra de vidro. Componentes biológicos comuns usados nesses estudos incluem aminoácidos e DNA. Funções computacionais podem ser executadas pela manipulação de reações químicas naturais encontradas nessas substâncias. O que é Computação Biológica? (computerhope. com)
No futuro, os biocomputadores poderão ser armazenados no DNA de células vivas. Essa tecnologia poderia armazenar quantidades quase ilimitadas de dados e permitir que os biocomputadores realizassem cálculos complexos além de nossas capacidades atuais.

A civilização está agora seguindo os passos da computação quântica. Ela será capaz de fornecer velocidade computacional sem precedentes com análise preditiva para resolver problemas. A tecnologia quântica, que usa as caracterizações exclusivas de partículas subatômicas para processar entradas de dados, provavelmente revolucionará tudo, desde segurança cibernética até análises em tempo real. A computação quântica pode ser direcionada e aumentada por meio de inteligência artificial, operar em uma estrutura 5G ou 6G, oferecer suporte à IoT e catalisar ciência de materiais, biotecnologia, genômica e o metaverso.
Os estudantes de Engenharia de Software viveram uma experiência no estilo do programa mundialmente conhecido “Shark Tank”. A atividade, comandada pelo professor Artur Veloso, envolveu os alunos do 1º e 2º período, pela disciplina de Cenários II, e do 7º, pela disciplina de Gerência.

Atividade contou com convidados de renome na tecnologia
Durante todo o período de 2022.2 os alunos foram envolvidos com a proposta do professor que culminou com a atividade final e teve convidados de renome na tecnologia e gestores de startups piauienses:
José Arthur – programador há mais de 25 anos e CEO da empresa de desenvolvimento de software “Interprise App tech” e André Junhson – Sócio da Obsis, empresa responsável por sistemas renomados como OB MED (conecta pacientes com consultas em consultórios) e a GoJus (sistema de automação para advogados).
Os estudantes desenvolveram a ideia de startup, expuseram a viabilidade com técnicas avançadas de gestão, como MVP (Produto Viável Mínimo), prepararam e apresentaram o Pitch para a banca julgadora.

Estudantes do 1º, 2º e 7º período participaram da atividade
A prática foi dividida em duas etapas:
1 – Os estudantes de 1º e 2º período foram divididos em grupos e ficaram responsáveis pela criação de startups. Já os grupos do 7º por gerir essas startups criadas pelos primeiros períodos.
Cada time de gestores tinha 3 a 4 startups sob sua responsabilidade. Cada startup se apresentou aos seus gestores, que por sua vez escolheram uma para representá-los na etapa final.
2 – Na última fase os convidados José Artur e André Junhson fizeram o papel de “tubarões”. Eles avaliaram tanto as startups como a gerência de cada uma delas.

A batalha de pitchs foi comandada pelo professor Artur Veloso
“Essa atividade foi pra mostrar para os estudantes como funciona o trabalho real na área de tecnologia, sobre o empreendedorismo e como fazer pitch, fora o próprio conhecimento das tecnologias, trabalho em equipe e afins”, explicou o professor Artur Veloso, que além de professor do iCEV é CEO da Sturtup Fábrica de Gênios e já apresentou um pitch de destaque na Rio Inovation Week.
Os “jurados” avaliaram as startups e suas gestões
O Shark Tank é um programa bastante popular em todo mundo. Muitos empreendedores participam do programa, para apresentarem suas ideias, projetos, produtos, serviços e até mesmo sua empresa, com o propósito de conseguir uma parceria com algum dos investidores participantes da bancada.
Os investidores que também são jurados do programa, chamados de tubarões – tradução em português para Shark – estão lá para avaliar se gostam da proposta dos empreendedores e decidir se irão ‘’comprar suas ideias’’, ou seja, se vão ou não investir.
Avenida Presidente Kennedy, 1100 - São Cristovão - 64052-335 - Teresina-PI
Telefone: (86) 9807-1976 - E-mail: contato.icev@somosicev.com