
Fonte: Exame
O Hackathon OLX é uma maratona digital para jovens universitários que vai acontecer virtualmente entre dos dias 16 e 25 de outubro. A iniciativa é fruto de uma parceria entre a OLX e o Hacktudo, festival de cultura digital, e se destina a jovens interessados em criar projetos a cerca do tema “Economia Colaborativa em Tempos de Pandemia”. As inscrições são gratuitas e devem ser realizadas até a próxima segunda-feira (28) pelo Sympla.
Podem participar do hackathon alunos universitários de cursos superiores de graduação em qualquer área do conhecimento e estudantes de cursos técnicos. Vale ressaltar que as inscrições só serão válidas para alunos com matrícula vigente. O evento ainda vai contar com prêmios em dinheiro para os três grupos finalistas, além de oferecer seminários online e sessões de mentoria para os participantes, que também vão concorrer a um Summer Job na OLX.
/i.s3.glbimg.com/v1/AUTH_08fbf48bc0524877943fe86e43087e7a/internal_photos/bs/2020/Z/1/mvDymmQjCp2yrPyVS3uA/brl-9944.jpg)
Abertura da Hackathon do festival Hacktudo 2019 — Foto: Divulgação/Hacktudo
Além disso, a participação no Hackathon OLX está limitada aos 30 primeiros times que se cadastrarem na maratona. As inscrições devem ser realizadas por grupos de três a quatro estudantes, e um dos integrantes da equipe deve ficar responsável pelo envio dos comprovantes de matrícula e documentos necessários de cada membro do grupo. Valem boletos bancários ou faturas de cartão de crédito que constem os débitos de pagamento do curso e carteirinhas de identificação ou declaração da instituição.
O concurso seguirá um cronograma definido. Durante a abertura do evento, no dia 16 de outubro, será anunciado um desafio para os participantes, que terão 36 horas para idealizar e desenvolver uma solução inovadora e criativa a partir de um projeto original e aplicável. Após esse período, as dez equipes que mais se destacarem seguirão para a próxima etapa, um pitching no dia 24 de outubro. Então, no dia 25, serão revelados os três melhores projetos. O hackathon também vai contar com sessões de mentoria e outras dinâmicas virtuais e o time vencedor ainda leva para casa R$ 5 mil.
Para inscrever seu time no Hackathon OLX, basta acessar o site
O Hackathon OLX é apenas uma das atividades previstas para o Hacktudo, festival de cultura digital que acontece online e gratuitamente entre os dias 16 e 25 de outubro. O evento ainda vai apresentar conferências com profissionais de grandes empresas de tecnologia e uma exposição virtual do artista Jota Azevedo sobre lixo eletrônico. A programação também inclui atividades exclusivas para as mulheres e para o público infanto-juvenil. Para saber todos os detalhes e se inscrever nos laboratórios, basta acessar: www.hacktudo.com.br

O desemprego segue em alta no Brasil, com 13 milhões de desocupados, ou 13,6% da população ativa do país. Mas não para todos. Para os profissionais ligados a áreas de tecnologia da informação, o ritmo é de aquecimento no mercado de trabalho, com alta de 63% segundo levantamento do Banco Nacional de Empregos, um portal de currículos com 135 mil empresas cadastradas.
Segundo esse levantamento, enquanto no ano passado, de janeiro a setembro, foram abertas 8.049 vagas, no mesmo período em 2020 a procura chegou a 12.682 postos – daí a alta de 63%.
Também de acordo com essa pesquisa, os estados de São Paulo (5.793), Santa Catariana (1.378), Paraná (1.105), Rio Grande do Sul (1.020) e Rio de Janeiro (858) são os que oferecem mais vagas no setor. Comparado com o ano passado, o aumento das vagas de TI em São Paulo foi de 138%.
“Com a maior opção por serviços delivery, internet e e-commerce, áreas diretamente ligadas à tecnologia tornaram-se necessárias dentro das empresas para que o atendimento continuasse acontecendo, o que consequentemente responde esse aumento de vagas na área de tecnologia”, aponta a pesquisa do BNE.
Publicado por Convergência Digital

Image Credits: Nigel Sussman
Unity Software Inc. is set to list on the New York Stock Exchange this month, following its S-1 filing two weeks ago. The 16-year-old tech company is universally known within the gaming industry and largely unknown outside of it. But Unity has been expanding beyond gaming, pouring hundreds of millions of dollars into a massive bet to be an underlying platform for humanity’s future in a world where interactive 3D media stretches from our entertainment experiences and consumer applications to office and manufacturing workflows.
Much of the press about Unity’s S-1 filing mischaracterizes the business. Unity is easily misunderstood because most people who aren’t (game) developers don’t know what a game engine actually does, because Unity has numerous revenue streams, and because Unity and the competitor it is most compared to — Epic Games — only partially overlap in their businesses.
Last year, I wrote an in-depth guide to Unity’s founding and rise in popularity, interviewing more than 20 top executives in San Francisco and Copenhagen, plus many other professionals in the industry. In this two-part guide to get up to speed on the company, I’ll explain Unity’s business, where it is positioned in the market, what its R&D is focused on and how game engines are eating the world as they gain adoption across other industries.
In part two, I’ll analyze Unity’s financials, explain how the company has positioned itself in the S-1 to earn a higher valuation and outline both the bear and bull cases for its future.
For those in the gaming industry who are familiar with Unity, the S-1 might surprise you in a few regards. The Asset Store is a much smaller business that you might think, Unity is more of an enterprise software company than a self-service platform for indie devs and advertising solutions appear to make up the largest segment of Unity’s revenue.
Unity’s origin is as a game engine, software that is similar to Adobe Photoshop, but used instead for editing games and creating interactive 3D content. Users import digital assets (often from Autodesk’s Maya) and add logic to guide each asset’s behavior, character interactions, physics, lighting and countless other factors that create fully interactive games. Creators then export the final product to one or more of the 20 platforms Unity supports, such as Apple iOS and Google Android, Xbox and Playstation, Oculus Quest and Microsoft HoloLens, etc.
In this regard, Unity is more comparable to Adobe and Autodesk than to game studios or publishers like Electronic Arts and Zynga.
Since John Riccitiello took over as CEO from co-founder David Helgason in 2014, Unity has expanded beyond its game engine and has organized activities into two divisions: Create Solutions (i.e., tools for content creation) and Operate Solutions (i.e., tools for managing and monetizing content). There are seven noteworthy revenue streams overall:
Aside from these three product categories, Unity is reporting another group of content creation offerings separately in the S-1 as “Strategic Partnerships & Other” (which accounts for further 9% of revenue):
Unity is compared most frequently to Epic Games, the company behind the other leading game engine, Unreal. Below is a quick overview of the products and services that differentiate each company. The cost of switching game engines is meaningful in that developers are typically specialized in one or the other and can take months to gain high proficiency in another, but some teams do vary the engine they use for different projects. Moving an existing game (or other project) over to a new game engine is a major undertaking that requires extensive rebuilding.
Epic has three main businesses: game development, the Epic Games Store, and the Unreal Engine. Epic’s core is in developing its own games and the vast majority of Epic’s $4.2 billion in 2019 revenue came from that (principally, from Fortnite). The Epic Games Store is a consumer-facing marketplace for gamers to purchase and download games; game developers pay Epic a 12.5% cut of their sales.
In those two areas of business, Unity and Epic don’t compete. While much of the press about Unity’s IPO frames Epic’s current conflict with Apple as an opportunity for Unity, it is largely irrelevant. A court order prevented Apple from blocking iOS apps made with Unreal in retaliation for Epic trying to skirt Apple’s 30% cut of in-app purchases in Fortnite. Unity doesn’t have any of its own apps in the App Store and doesn’t have a consumer-facing store for games. It’s already the default choice of game engine for anyone building a game for iOS or Android, and it’s not feasible to switch the engine of an existing game, so Epic’s conflict does not create much of a new market opening.
Let’s compare the Unity and Unreal engines:
Origins: Unreal was Epic’s proprietary engine for the 1998 game Unreal and was licensed to other PC and console studios and became its own business as a result of its popularity. Unity launched as an engine for indie developers building Mac games, an underserved niche, and expanded to other emerging market segments considered irrelevant by the core gaming industry: small indie studios, mobile developers, AR & VR games. Unity exploded in global popularity as the main engine for mobile games.
Programming Language: Based in the C++ programming language, Unreal requires more extensive programming than Unity (which requires programming in C#) but enables more customization, which in turn enables higher performance.
Core Markets: Unreal is much more popular among PC and console game developers; it is oriented toward bigger, high-performance projects by professionals. That said, it is establishing itself firmly in AR and VR and proved with Fortnite it can take a console and PC game cross-platform to mobile. Unity dominates in mobile games — now the largest (and fastest growing) segment of the gaming industry — where it has over 50% market share and where Unreal is not a common alternative. Unity has kept the largest market share in AR and VR content, at over 60%.
Ease of Authoring: Neither engine is easy for a complete novice, but both are fairly straightforward to navigate if you have basic coding abilities and put the time into experimenting and watching tutorials. Unity has prioritized ease of use since its early days, with a mission of democratizing game development that was so concentrated among large studios with large budgets, and ease of authoring remains a key R&D focus. This is why Unity is the common choice in educational environments and by individuals and small teams creating casual mobile games. Unity lets you see but not edit the engine’s source code unless you pay for an enterprise subscription; this protects developers from catastrophic mistakes but limits customization. Unreal isn’t dramatically more complex but, as a generalization, it requires more lines of code and technical skill. It is open source code so can be completely customized. Unreal has a visual scripting tool called Blueprint to conduct some development without needing to code; it’s respected and often used by designers though not a no-code solution to developing a complex, high-performance game (no one offers that). Unity recently rolled out its own visual scripting solution for free called Bolt.
Pricing: While Unity’s engine operates on a freemium subscription model (then has a portfolio of other product offerings), Unreal operates on a revenue-share, taking 5% of a game’s revenue. Both have separately negotiated pricing for companies outside of gaming that aren’t publicly disclosed.
Many large gaming companies, especially in the PC and console categories, continue to use their own proprietary game engines built in-house. It is a large, ongoing investment to maintain a proprietary engine, which is why a growing number of these companies are switching to Unreal or Unity so they can focus more resources on content creation and tap into the large talent pools that already have mastery in each one.
Other game engines to note are Cocos2D (an open source framework by Chukong Technologies that has a particular following among mobile developers in China, Japan, and South Korea), CryEngine by Crytek (popular for first-person shooters with high visual fidelity), and Amazon’s Lumberyard (which was built off CryEngine and doesn’t seem to have widespread adoption, or command much respect, among the many developers and executives I’ve spoken to).
For amateur game developers without programming skills, YoYo Games’ GameMaker Studio and Scirra’s Construct are both commonly used to build simple 2D games (Construct is used for HTML5 games in particular); users typically move on to Unity or Unreal as they gain more skill.
There remain a long list of niche game engines in the market since every studio needs to use one and those who build their own often license it if their games aren’t commercial successes or they see an underserved niche among studios creating similar games. That said, it’s become very tough to compete with the robust offerings of the industry standards — Unity and Unreal — and tough to recruit developers to work with a niche engine.
User-generated content platforms for creating and playing games like Roblox (or new entrants like Manticore’s Core and Facebook Horizon) don’t compete with Unity — at least for the foreseeable future — because they are dramatically simplified platforms for creating games within a closed ecosystem with dramatically more limited monetization opportunity. The only game developers these will pull away from Unity are hobbyists on Unity’s free tier.
I’ve written extensively on how UGC-based game platforms are central to the next paradigm of social media, anchored within gaming-centric virtual worlds. But based on the overall gaming market growth and the diversity of game types, these platforms can continue to soar in popularity without being a competitive threat to the traditional studios who pay Unity for its engine, ad network, or cloud products.
For the last three years, Unity has been creating its “data oriented technology stack,” or DOTS, and gradually rolling it out in modules across the engine.
Unity’s engine centers on programming in C# code which is easier to learn and more time-saving than C++ since it is a slightly higher level programming language. Simplification comes with the trade off of less ability to customize instruction by directly interacting with memory. C++, which is the standard for Unreal, enables that level of customization to achieve better performance but requires writing a lot more code and having more technical skill.
DOTS is an effort to not just resolve that discrepancy but achieve dramatically faster performance. Many of the most popular programming languages in use today are “object-oriented,” a paradigm that groups characteristics of an object together so, for example, an object of the type “human” has weight and height attached. This is easier for the way humans think and solve problems. Unity takes advantage of the ability to add annotations to C# code and claims a proprietary breakthrough in understanding how to recompile object-oriented code into “data-oriented” code, which is optimized for how computers work (in this example, say all heights together and all weights together). This is orders of magnitude faster in processing the request at the lowest level languages that provide 1s-and-0s instructions to the processor.
This level of efficiency should, on one hand, allow highly-complex games and simulations with cutting-edge graphics to run quickly on GPU-enabled devices, while, on the other hand, allowing simpler games to be so small in file size they can run within messenger apps on the lowest quality smartphones and even on the screens of smart fridges.
Unity is bringing DOTS to different components of its engine one step at a time and users can opt whether or not to use DOTS for each component of their project. The company’s Megacity demo (below) shows DOTS enabling a sci-fi city with hundreds of thousands of assets rendered in real-time, from the blades spinning on the air conditioners in every apartment building to flying car traffic responding to the player’s movements.
The forefront of graphics technology is in enabling ray tracing (a lighting effect mimicking the real-life behavior of light reflecting off different surfaces) at a fast enough rendering speed so games and other interactive content can be photorealistic (i.e. you can’t tell it’s not the real world). It’s already possible to achieve this in certain contexts but takes substantial processing power to render. Its initial use is for content that is not rendered in real-time, like films. Here are videos by both Unity and Unreal demonstrating ray tracing used to make a digital version of a BMW look nearly identical to video of a real car:
To support ray-tracing and other cutting-edge graphics, Unity released its High Definition Render Pipeline in 2018. It gives developers more powerful graphics rendering for GPU devices to achieve high visual fidelity in console and PC games plus non-gaming uses like industrial simulations. (By comparison, its Universal Render Pipeline optimizes content for lower-end hardware like mobile phones.)
Unity’s Research Labs team is focused on the next generation of authoring tools, particularly in an era of AR or VR headsets being widely adopted. One component of this is the vision for a future where nontechnical people could develop 3D content with Unity solely through hand gestures and voice commands. In 2016, Unity released an early concept video for this project (something I demo-ed at Unity headquarters in SF last year):
The term “game engine” limits the scope of what Unity and Unreal are already used for. They are interactive 3D engines used for practically any type of digital content you can imagine. The core engine is used for virtual production of films to autonomous vehicle training simulations to car configurators on auto websites to interactive renderings of buildings.
Both of these engines have long been used outside gaming by people repurposing them and over the last five years Unity and Unreal have made expanding use of their engines in other industries a top priority. They are primarily focused on large- and mid-size companies in 1) architecture, engineering, and construction, 2) automotive and heavy manufacturing, and 3) cinematic video.
In films and TV commercials, game engines are used for virtual production. The settings, whether animated or scanned from real-world environments, are set up as virtual environments (like those of a video game) where virtual characters interact and the camera view can be changed instantaneously. Human actors are captured through sets that are surrounded by the virtual environment on screens. The director and VFX team can change the surroundings, the time of day, etc. in real-time to find the perfect shot.
There are a vast scope of commercial uses for Unity since assets can be imported from CAD, BIM, and other formats and since Unity gives you the ability to build a whole world and simulate changes in real-time. There are four main use cases for Unity’s engine beyond entertainment experiences:
Unity’s ambitions beyond gaming ultimately touch every facet of life. In his 2015 internal memo in favor of acquiring Unity, Facebook CEO Mark Zuckerberg wrote “VR / AR will be the next major computing platform after mobile.” Unity is currently in a powerful position as the key platform for developing VR / AR content and distributing it across different operating systems and devices. Zuckerberg saw Unity as the natural platform off which to build “key platform services” in the mixed reality ecosystem like an “avatar / content marketplace and app distribution store”.
If Unity maintains its position as the leading platform for building all types of mixed reality applications into the era when mixed reality is our main digital medium, it stands to be one of the most important technology companies in the world. It would be the engine everyone across industries turns to for creating applications, with dramatically larger TAM and monetization potential for the core engine than is currently the case. It could expand up the stack, per Zuckerberg’s argument, into consumer-facing functions that exist across apps, like identify, app distribution, and payments. Its advertising product is already in position to extend into augmented reality ads within apps built with Unity. This could make it the largest ad network in the AR era.
This grand vision is still far away though. First, the company’s expansion beyond gaming is still early in gaining traction and customers generally need a lot of consulting support. You’ll notice other coverage of Unity over the last few years all tends to mention the same case studies of use outside gaming; there just aren’t that many than have been rolled out by large companies. Unity is still in the stage of gaining name recognition and educating these markets about what its engine can do. There are promising proof points of its value but market penetration is small.
Second, the era of AR as “the next major computing platform after mobile” seems easily a decade away, during which time existing and yet-to-be-founded tech giants will also advance their positions in different parts of the AR tech, authoring, and services stack. Apple, Facebook, Google, and Microsoft are collaborators with Unity right now but any of them could decide to compete with their own AR-focused engine (and if any of them acquire Unity, the others will almost certainly do so because of the loss of Unity’s neutral position between them).
Published by Techcrunch

Como uma das linguagens de programação mais populares, python tem um grande número de bibliotecas excelentes que facilitam o desenvolvimento como Pandas, Numpy, Matplotlib, SciPy, etc.
No entanto, neste artigo, vou apresentar a vocês algumas bibliotecas que são mais interessantes do que muito úteis. Acredito que essas bibliotecas podem mostrar outro aspecto do Python e o prosperar da comunidade.
Honestamente, quando vejo esta biblioteca pela primeira vez, questionei por que as pessoas podem precisar disso? Bashplotlib é uma biblioteca Python que nos permite traçar dados em um ambiente stdout de linha de comando.
Logo percebi que provavelmente será útil quando você não tiver nenhuma GUI disponível. Bem, este cenário pode não ser tão frequente, mas não impede minha curiosidade e sentir que é uma biblioteca Python muito interessante.
Bashplotlib pode ser facilmente instalado com .pip
pip install bashplotlib
Vamos ver alguns exemplos. No código abaixo, eu importei para gerar algumas matrizes aleatórias, bem como o , é claro.numpybashplotlib
import numpy as np
from bashplotlib.histogram import plot_hist
arr = np.random.normal(size=1000, loc=0, scale=1)
plot_hist é uma função a partir disso é para plotar dados 1D em um histograma, assim como faz em Matplotlib. Então, eu uso Numpy gerou uma matriz aleatória com 1.000 números que normalmente são distribuídos. Depois disso, podemos facilmente traçar esses dados da seguinte forma:bashplotlibplt.hist
plot_hist(arr, bincount=50)
A saída é assim

Não é interessante? 🙂
Além disso, você pode traçar seus dados em um gráfico de dispersão de arquivos de texto

O Bashplotlib que acabei de introduzir é para traçar dados no ambiente de linha de comando, enquanto PrettyTable é para tabela de saída em um formato bonito.
Da mesma forma, podemos facilmente instalar esta biblioteca usando .pip
pip install prettytable
Em primeiro lugar, vamos importar a liberdade.
from prettytable import PrettyTable
Então, podemos usar para criar um objeto de tabela.PrettyTable
table = PrettyTable()
Uma vez que tenhamos o objeto de tabela, podemos começar a adicionar campos e linhas de dados.
table.field_names = ['Name', 'Age', 'City']
table.add_row(["Alice", 20, "Adelaide"])
table.add_row(["Bob", 20, "Brisbane"])
table.add_row(["Chris", 20, "Cairns"])
table.add_row(["David", 20, "Sydney"])
table.add_row(["Ella", 20, "Melbourne"])
Para exibir a mesa, basta imprimi-la!
print(table)

table.align = 'r' print(table)
Classificar a tabela por uma coluna
table.sortby = "City" print(table)
Você pode até mesmo obter sequência HTML da tabela

Esta biblioteca não é apenas muito interessante, mas também muito útil, na minha opinião. Muitas vezes você pode querer implementar um recurso de pesquisa “confuso” para o seu programa. FuzzyWuzzy fornece uma solução fora da caixa e leve para isso.
Instale-o como de costume.pip
pip install fuzzywuzzy
Importar a biblioteca:
from fuzzywuzzy import fuzz
Vamos fazer um teste simples.
fuzz.ratio(“Let’s do a simple test”, “Let us do a simple test”)

Como mostrado o resultado “93” significa que essas duas cordas têm 93% de semelhança, o que é bastante alto.
Quando você tem uma lista de strings, e você quer pesquisar um termo contra todos eles, FuzzyWuzzy vai ajudá-lo a extrair as mais relevantes com suas semelhanças.
from fuzzywuzzy import processchoices = ["Data Visualisation", "Data Visualization", "Customised Behaviours", "Customized Behaviors"]process.extract("data visulisation", choices, limit=2) process.extract("custom behaviour", choices, limit=2)
No exemplo acima, o parâmetro diz fuzzyWuzzy para extrair os resultados “top n” para você. Caso contrário, você terá uma lista de tuplas com todas essas cordas originais e suas pontuações de semelhança.limit
Você geralmente desenvolve ferramentas de linha de comando usando Python? Se assim for, esta interessante biblioteca vai ajudá-lo quando sua ferramenta CLI está processando algo demorado, mostrando uma barra de progresso para indicar o quanto foi feito.
Instalação usando, novamente.pip
pip install tqdm
Quando você tiver uma função de uso de loop, basta substituí-la por tqdm.rangetrange
from tqdm import trangefor i in trange(100): sleep(0.01)
De forma mais geral, você pode querer fazer um loop de uma lista. Isso também é fácil com tqdm.
from tqdm import tqdm for e in tqdm([1,2,3,4,5,6,7,8,9]): sleep(0.5) # Suppose we are doing something with the elementstqdm funciona não apenas para o ambiente de linha de comando, mas também iPython/Jupyter Notebook.

Deseja adicionar algumas cores aos seus aplicativos de linha de comando? Colorama torna muito fácil produzir tudo na sua cor preferida.
Instalar o Colorama precisa de novo.pip
pip install colorama
O Colorama suporta renderizar a cor do texto de saída em “primeiro plano” (a cor do texto), “fundo” (a cor de fundo) e “estilo” (estilo extra da cor). Podemos importar
from colorama import Fore, Back, Style
Em primeiro lugar, vamos mostrar alguns avisos usando a cor amarela.
print(Fore.YELLOW)
print("This is a warning!")
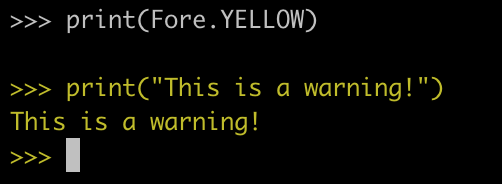
Então, vamos tentar mostrar alguns erros usando uma cor de fundo vermelho.
print(Back.RED + Fore.WHITE + "This is an error!")

Esse vermelho é muito brilhante. Vamos usar o estilo “dim”.
print(Back.RESET + Style.DIM + "Another error!")
Aqui estamos definindo “RESET” para voltar a alterar a cor de fundo para padrão.

O estilo “DIM” torna a fonte meio invisível. Quando quisermos mudar tudo de volta ao normal, basta definir “Estilo” para “RESET_ALL”
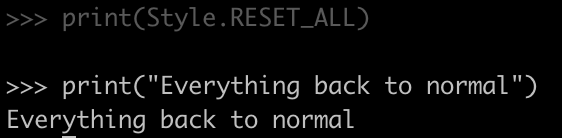
Graças a esses desenvolvedores de código aberto que contribuem para a comunidade Python e a prosperam.
Antes de ver a biblioteca Bashplotlib, tenho que dizer que nunca tive essa ideia de traçar dados em um ambiente de linha de comando. Não importa se pode ou não ser útil para você, eu diria que a diversidade das ideias de desenvolvimento e criativos das pessoas nunca terminou.
A vida é curta, use Python!
Publicado por Medium

Para se preparar para as demandas do mercado pós-pandemia, a Accenture está com 556 vagas abertas para trabalho remoto na área de tecnologia.
A consultoria se antecipa às tendências na área de computação em nuvem, prevendo que as companhias vão investir mais em tecnologias para a transformação digital.
“Quem não fez isso antes, sofreu mais agora. Com a crise, as empresas precisarão de investimentos certeiros para resolver seus problemas e se adaptar. Na migração de seus sistemas para a nuvem, mais do que nunca vão precisar também manter a segurança de informações e a privacidade de dados”, comenta a diretora executiva Flavia Picolo.
Aproveitando os aprendizados com o home office na quarentena, a empresa quer atrair os profissionais da área oferecendo oportunidades para trabalhar de casa.
“O profissional de tecnologia sempre teve uma super demanda, e que agora será ainda maior. Não estamos buscando apenas o especialista em Cloud, mas todos os componentes da área, como desenvolvedores backend e frontend”, diz a diretora.
Além da parte técnica, eles também valorizam pessoas com habilidades comportamentais para se encaixar na cultura da Accenture e na nova forma de trabalho. O destaque é para um perfil empreendedor, criativo e com vontade de inovar.
A flexibilidade da empresa se estende para os benefícios e a recepção dos contratados. Todos poderão personalizar o kit de equipamentos para ter todo o suporte em casa que teriam nos escritórios.
A ideia é que profissionais de qualquer lugar do Brasil possam se candidatar às vagas. Não tem internet boa em casa? Precisa de cadeira, apoio de pé, teclado e mouse? A empresa vai ajudar com isso.
“Além dos equipamentos, não queremos que eles percam o acesso a conhecimento que todos têm na empresa. Os novos contratados terão treinamentos online, certificação em cloud e mentores para acompanhar a carreira. Nada se perde nesse processo, apenas se soma”, explica ela.
Para a diretora, essa também será uma oportunidade para que mais mulheres possam seguir a carreira na área de TI. O trabalho em casa será aliado a horários mais flexíveis, o que facilita o equilíbrio entre o serviço e responsabilidades com a família.
As vagas tem como requisito conhecimento em Java, Angular, Mobile, React, iOS, Cloud ou DevOps. Saiba mais e se inscreve pelo site.
A área de TI, em particular a de programação, é uma das que mais contrata no Brasil mesmo com a crise. Até 2024, a projeção era de ao menos 70 mil novos postos de trabalho por ano, um crescimento ao redor de 10%, segundo a Brasscom, associação de empresas do setor.
As crises sanitária e econômica de 2020 podem mudar em algo as projeções, mas o essencial continua: vai faltar gente capacitada para trabalhar com tecnologia no Brasil. A escassez é mais aguda entre profissionais da chamada “ciência de dados”, dedicada aos softwares para análise de uma quantidade enorme de informações.
Publicado por Exame

Ter dificuldades é um processo comum para todos em fase de aprendizado da programação. Não tem problema se você cometeu erros, o mais importante é aprender com eles para tornar-se um profissional de excelência. Galera de Engenharia de Software, essas dicas são para vocês:
1. Tenha sua razão
Se você quer começar a programar, tem que ter uma razão. Você gosta de escrever código ou quer ter uma carreira mais lucrativa.
Programação não é simples, você vai ficar frustrado muitas vezes. Será essencial manter essa razão em mente para seguir em frente.
2. Construa uma base sólida
Antes de começar, revise alguns conceitos, a maior parte da programação é construída em matemática 1, funções e variáveis.
3. Encontre um grupo
Será útil para apoiá-lo quando começar. Será valioso porque outras pessoas estarão no mesmo lugar que você.
4. Divida os problemas
Uma das partes mais importantes da programação é pegar um grande problema e dividi-lo em partes cada vez menores até que essas partes sejam solucionáveis.
5. Pseudocódigo (pseudocoding)
Muitas vezes é útil escrever em detalhes o que você está tentando fazer em palavras simples antes de tentar escrever código.
6. Abrace o ciclo de aprendizagem
Se você está aprendendo a programar como uma segunda carreira, aprender a aprender será uma grande parte do seu processo.
Há muitos altos e baixos envolvidos, o que é muito natural! Se prepare para aquela montanha-russa antes de começar.
7. Comece com recursos gratuitos
Há um milhão de recursos para aprender a codificar. Alguns são gratuitos e alguns são pagos. Certifique-se de escrever código, e depois disso, você poderia pensar em recursos pagos.
8. Encontre o seu nicho
Há muitos mundos dentro da programação, encontrar um mundo que você ama e focar nisso, em vez de tentar aprender 8 linguagens de programação, todos os editores e ferramentas de desenvolvimento, etc.
9. Seja bom em reconhecimento de padrões
Reconhecer padrões no código é uma das habilidades mais importantes que você pode ter.
10. Faça bons hábitos cedo
Será mais fácil escrever código limpo no futuro se você adquirir o hábito cedo. Maus hábitos podem ser difíceis de quebrar. Um hábito pode influenciar no seu código.
Umas das formas prazerosas e acessíveis de aprender coisas novas é pelo Youtube, então aí vai algumas dicas de canais para programadores:
– Rocketseat
– WP Masters
– Rodrigo Branas
– Código Fonte TV
– RB Tech
– Danki Code
– Filipe Deschamps
– Lucas Montano
– CFB Cursos
– DEV Media
– Vinícius Thiego
– Cursos em Vídeo

Aprender termos básicos são essências para a evolução nos estudos e na profissão de programador. Confira alguns termos nesse dicionário da programação que nós do iCEV preparamos para você.
Algorithm
Um algoritmo é uma fórmula ou conjunto de etapas para resolver um problema específico.
API
A interface de programação de aplicatívos é uma maneira de os apps emprestarem funcionalidades e dados uns para os outros.
Array
São usados para armazenar vários valores em uma única variável.
Boolean
Uma expressão que resulta em um valor VERDADEIRO ou FALSO.
Breakpoint
A localização no código de programação que, quando alcançada, dispara uma parada temporária no programa.
Bug
Um “bug” é u m erro ou defeito de software ou hardware que causa mau funcionamento de um programa.
Class
Uma classe é uma descrição que abstrai um conjunto de objetos com características similares.
Caia
Chamar uma rotina em uma linguagem de programação. Chamar uma rotina consiste em especificar o nome da rotina e, opcionalmente, os parâmetros.
Character
No software de computador, qualquer símbolo que exija um byte de armazenamento.
Data Structure
Na programação, o termo estrutura de dados refere-se a um esquema para organizar informações relacionadas.
Data Type
Classificação de um tipo específico de informação. É fácil para os humanos distinguir entre diferentes tipos de dados.
Decode
Decodificação refere-se à reversão do processo de um método de codificação.
Encapsulamento
Empacotamento de dados e métodos em um único componente.
Exception (Exceção)
Um erro que ocorre durante a execução de um programa.
Exponenciação
A potenciação ou exponenciação é a operação de elevar um número ou expressão a uma dada potência.
Feature (Característica)
Uma propriedade notável de um dispositivo ou aplicativo de software.
Float
Um número com um ponto decimal.
Function (Função)
Um bloco de código reutilizável parametrizado que executa uma tarefa.
Gamification
Gamificação significa usar técnicas de design de jogos digitais em contextos que não são de jogos, como educação, negócios ou social.
Garbage Collection
Coletor de lixo é um processo usado para a automação do gerenciamento de memória.
Geek
Abreviação de nerd de computador, um indivíduo apaixonado por computadores, com exclusão de outros interesses humanos normais.
Hacker
Um termo de gíria para um entusiasta de computadores, ou seja, uma pessoa que gosta de aprender linguagens de programação e sistemas de computador e pode frequentemente ser considerado ] um especialista no (s) assunto (s).
Hard Disk
Um disco magnético no qual você pode armazenar dados do computador. O termo hard é usado para diferencia-lo de um disco flexível ou flexível.
Hardware
Refere-se a objetos nos quais você pode realmente tocar, como discos, unidades de disco, telas, teclados, impressoras, placas e chips. Por outro lado, o software é intocável.
I/O – input/output
Abreviação de entrada/saída. O termo E/S é usado para descrever qualquer programa, operação ou dispositivo que transfira dados para ou de um computador e para ou de um dispositivo periférico.
loT
loT é a abreviação de Internet das Coisas. Refere-se à crescente rede de objetos físicos que apresentam um endereço IP para Internet.
Java
Java é uma linguagem de programação de alto nível e uso geral desenvolvida pela Sun Microsystems.
Javascript
JavaScript é uma linguagem de script desenvolvida pela Netscape para permitir que autores da Web projetem sites e sistemas interativos.
Json
Abreviagao deJavaScript Object Notation,JSON 6 um formato leve de intercâmbio de dados que é fácil para humanos lerem e escreverem e para máquinas analisarem e gerarem.
KB – kilobyte
Abreviação de kilobyte. Quando usado para descrever o armazenamento de dados, o KB geralmente representa 1 .024 bytes.
Kbps – kilobits per second
Abreviação de kilobits por segundo, uma medida da velocidade de transferência de dados. Modems.por exemplo, são medidos em Kbps.
Kernel
O kernel é o módulo central de um sistema operacional (SO). É a parte do sistema operacional que carrega primeiro e permanece na memória principal.
Label
Um rótulo! Há muitas aplicações para esse termo na área de TI.
LAMP
Shortfor Linux, Apache, MYSQL and PHP, uma plataforma/pilha open-source para desenvolvimento web.
Latency – Latência
Na rede, a quantidade de tempo que um pacote leva para viajar da origem ao destino.
Quando necessitamos planejar algo que visa a um objetivo ou produto específico, chamamos isso de Projeto. Podemos ter projetos mais simplistas, como a reforma de um cômodo de nossa casa, ou até mesmo projetos complexos, como o desenvolvimento de um sistema para mapeamento por meio de Geolocalização de celulares de identificação de possíveis casos de COVID-19.
O Gerenciamento de Projeto tem como objetivo o planejamento das ações, a sua execução e o controle de diversas atividades para alcançar os objetivos especificados de maneira sistematizada e organizada.
Existem métodos e ferramentas que são utilizadas nas atividades de Gerenciamento de Projetos, alguns em todo o ciclo, outros em alguma fase. Partindo deste pressuposto, o Modelo CEK foi concebido a partir da integração das ferramentas Canvas, Estrutura Analítica do Projeto e Kanban, daí a origem do nome do Modelo. Desta forma, o projeto é norteado desde a sua concepção, a fase de levantamento de requisitos, até a sua plena execução de forma controlável e efetiva.
O Modelo CEK foi inicialmente abordado em um livro de autoria do professor Luciano Aguiar, em conjunto com os pesquisadores Fernando Escobar (PMI – DF), Washington Almeida (Unb – Brasília), Aíslan Rafael (IFPI – Picos) e Pedro César, publicado no Encontro Regional de Computação do Ceará, Maranhão e Piauí no ano de 2019.
O modelo pode transformar ideias em projetos colaborativos, ágeis, controláveis e efetivos.
O propósito desse modelo é agregar as melhores características dessas três ferramentas e percorrer todo o ciclo de vida de um projeto, não se esgotando a sua utilização apenas na Engenharia de Software.
Uma das áreas de estudo da Engenharia de Software é a Engenharia de Requisitos, e esse é um dos principais problemas da área: a má utilização de técnica já reconhecidas para o levantamento, descoberta e validação das necessidades dos usuários e cliente do produto de software que será entregue pelo projeto.
Como resposta a este cenário, fundamentado na abordagem por projetos aplicada à engenharia de software, em um método híbrido que combina elementos das abordagens tradicional e ágil, o Modelo CEK.
Trata-se da proposição da integração de diferentes ferramentas de gestão, de forma a mitigar os problemas relacionados ao desenvolvimento de software, em especial às falhas no levantamento de requisitos e definição de objetivos, à comunicação ineficiente entre equipe e clientes, com foco na ideação, planejamento e monitoramento da execução, reduzindo desperdícios, transformando ideias em projetos colaborativos, ágeis, controláveis e efetivos.
O que é cada ferramenta?*
Para entender melhor o modelo CEK é necessário conhecer cada uma das ferramentas.

Diagrama de integração das ferramentas. – Modelo CEK (Canvas + EAP + Kanban)
Nesse modelo, a fase inicial do projeto é o levantamento de requisitos da solução, se fosse aplicado à Engenharia de Software, mas no contexto mais amplo de projetos e com a utilização do Canvas de Projeto, essa fase é nomeada de ideação, ou seja, fase de brainstorming de ideias.
A história dos Canvas (isso mesmo, existem vários) surgiu no vale do silício americano com o Canvas de Modelo de Negócio, ou Business Model Canvas – BBMC. O Canvas de Projeto, que é utilizado no nosso modelo, já é uma adaptação do BMC proposta pelos professores Wankes e Helber.

O objetivo desse Canvas é envolver os stakeholders para o engajamento na formulação do projeto. Assim, com esse envolvimento das pessoas, a taxa de sucesso dos projetos tende a crescer. E como funciona? São feitas sessões guiadas por um facilitador para fechar o escopo inicial do projeto, preenchendo cada um dos blocos apresentados na figura acima.
EAP
Seguindo nas fases do modelo, agora a Estrutura Analítica do Projeto (EAP) ou em inglês WBS, que vem do PMBOK, Corpo de Conhecimento de Gerenciamento de Projetos.
A EAP é uma decomposição hierárquica de todo o escopo do projeto (trabalho total) que precisa ser executado pelo time do projeto a fim de produzir as entregas necessárias e satisfazer às necessidades das partes interessadas – cada nível descendente da EAP representa uma definição mais detalhada do nível mais alto correspondente e, ao final, de todo o trabalho do projeto.
Com a EAP busca-se a divisão dos pacotes de trabalho em uma análise bottom-up, sendo que ao final dessa etapa teremos todos os itens do backlog que serão monitorados com o uso do quadro Kanban.
Kanban
O Kanban teve origem na década de 40 do século passado no Japão, implementado em processos de manufatura e depois na indústria automobilística, em especial na empresa Toyota. É um método visual de gerenciamento de fluxo de trabalho para gerenciar as atividades de maneira eficaz.
A representação visual dos itens de trabalho em um quadro Kanban permite que os membros da equipe saibam o estado atual de cada item de trabalho a qualquer momento
O quadro Kanban apresenta de forma gráfica as atividades e em que estágio cada uma delas está no momento. No modelo CEK servirá para o controle dos entregáveis e aferição de desempenho das entregas.

Os itens ainda não iniciados, que compõem o backlog do projeto, são dispostos na coluna “a fazer”, conforme priorizados e com seu trabalho iniciado são movidos para a coluna ”fazendo”, uma vez concluídos, são movidos para a coluna “feito”. A sistemática, quando aplicada, garante um sistema puxado e de fluxo contínuo, e ainda identifica visualmente as fases que estão com problema.
O Modelo CEK adota a sistemática do Quadro Kanban, com os Pacotes de Trabalho da EAP, ainda não priorizados, sendo dispostos na coluna “a fazer” (compondo o backlog do projeto); os Pacotes de Trabalho já priorizados e que tiveram seu trabalho iniciado (limitados a um Pacote de Trabalho por equipe ou responsável – em atenção ao limite do Work In Progress) são movidos para a coluna “fazendo”, até que sejam concluídos e pontuados como “feito” – à medida que os cartões são movidos para a coluna “feito”, novos espaços são liberados para o “fazendo”, em um sistema puxado e de fluxo contínuo.
O fundamento da adoção do Kanban, que complementa a abordagem proposta pelo Modelo CEK – de transformar ideias em projetos colaborativos, ágeis, controláveis e efetivos – é justamente controlar a execução do projeto por meio do acompanhamento da execução dos pacotes de trabalho, definidos de forma colaborativa na EAP, derivados da concepção idealizada, também de forma colaborativa no Canvas.
A junção das ferramentas busca a redução de desperdícios, a melhoria na comunicação, a agilidade do fluxo contínuo e puxado, e a efetividades dos projetos de software.
Ele propõe a integração dessas três ferramentas ao longo do ciclo de vida de um projeto, visando de forma assertiva a melhoria no controle e por consequência na efetividade do produto criado.
Nesse contexto, o modelo ajuda na construção de um modelo adaptável à realidade das organizações e que sua utilização possa trazer transformação de ideias em projetos colaborativos, ágeis, controláveis e efetivos, que são características de cada uma das ferramentas integrantes do modelo: o Canvas de Projeto, a EAP e o Kanban.
Maiores detalhes do Modelo CEK podem ser encontrados no endereço: http://www.modelocek.com.br

Autores: Luciano Aguiar, Washington Almeida e Fernando Escobar

“PAC-MAN”, CONHECIDO NO BRASIL COMO “COME-COME”, FOI UM DOS JOGOS MAIS POPULARES DE TODOS OS TEMPOS
Em 2018, os games se tornaram mais lucrativos do que a indústria de Hollywood e a indústria musical combinadas, movimentando US$ 137 bilhões globalmente. A NewZoo, principal empresa de pesquisa da indústria dos games, projeta uma movimentação de US$ 152 bilhões até o final de 2019, um aumento de 9,6% em relação ao ano anterior.

Dominando a cultura pop, os games foram além do mero entretenimento e, além de serem um negócio lucrativo, influenciaram o desenvolvimento de aplicativos de uso cotidiano e se tornaram ferramenta de ensino em escolas.
A indústria dos videogames, ou o universo dos games, é composta por três partes: as empresas que fabricam as tecnologias que suportam os jogos; os estúdios que desenvolvem os títulos; e a comunidade que consome os games.
Um game pode ser jogado em diversas plataformas. As tecnologias que suportam os jogos podem ser divididas em três categorias:
– Mobile: celulares, tablets e outros dispositivos móveis
– Consoles: equipamentos fabricados especificamente para o suporte de games. Atualmente, três empresas são as principais no mercado de consoles: a Sony, com o PlayStation; a Microsoft, com o Xbox; e a Nintendo, com o Switch.
– PCs: computadores de uso pessoal também podem ser usados para jogar os mais diversos tipos de jogos
Um estudo da empresa de consultoria Limelight publicado em março de 2019 demonstrou que as plataformas mobile são as mais populares entre os jogadores, com os celulares sendo os dispositivos preferidos para o ato de jogar. A pesquisa foi feita a partir de entrevista com 4.500 pessoas de nove países.
Os consoles são divididos por gerações. Em 2019, eles estão na oitava geração, com uma nona chegando a partir de 2020. O PlayStation 4 é o console mais popular da oitava geração, tendo vendido 91,6 milhões de unidades entre novembro de 2013 e dezembro de 2018.
Os jogos de videogame podem ser divididos em gêneros, com propostas, atmosferas e mecânicas individuais. Em 2018, a empresa de pesquisa de mercado TechNavio fez um estudo detalhado do estado atual do mercado de games no mundo, a partir de dados vindos das desenvolvedoras, do varejo, dos governos e de publicações que estudam os games.
A pesquisa demonstrou que os jogos de ação são os mais populares entre os gamers, seguidos dos jogos de esporte e dos jogos no estilo battle royale, no qual todos os jogadores precisam ser derrotados, garantindo a vitória de apenas um indivíduo. Outros gêneros e subgêneros populares no mundo dos games são:
– FPS: sigla para first person shooter, o atirador em primeira pessoa. Nesses jogos, o jogador assume o papel e o ponto de vista de um personagem munido de armas, atrás de um objetivo. A franquia “Call of Duty” se encaixa na definição, colocando os jogadores em um ambiente de guerra. É um subgênero dos jogos de ação.
– Survival horror: nesse gênero, o jogador precisa sobreviver aos ataques de monstros, psicopatas e criaturas sobrenaturais, podendo ou não combatê-los. A franquia “Resident Evil” faz parte desse subgênero, trazendo para o jogador o desafio de sobreviver a um mundo tomado por zumbis.
– Jogos de ritmo: nesses títulos, o jogador precisa demonstrar coordenação motora para cumprir algum desafio. A franquia “Just Dance” pode ser definida dentro desse gênero, desafiando os jogadores a realizarem a coreografia de diversas músicas populares.
– RPG: sigla para role-playing game, ou jogo de interpretação de papéis. Nesse gênero, surgido nos jogos de tabuleiro, o jogador assume a identidade de um personagem, tomando decisões que influenciam no desenrolar da história apresentada. A franquia “The Witcher” se encaixa dentro do universo dos RPGs.
Os eSports, disputas dentro do universo dos mais diversos jogos, têm ganhado força e se profissionalizado no mundo todo.
O site Twitch é a principal plataforma de streaming de disputas de jogos online. Segundo a ISPO, empresa de pesquisa do mercado esportivo, o jogo mais popular no serviço em 2019 é “Fortnite”, título presente nos computadores, consoles e plataformas mobile.
Além de “Fornite”, os jogos “League of Legends”, “Rainbow Six Siege”, “Dota 2”, “Overwatch” e “Counter-Strike: Global Offensive” são populares entre os competidores de esportes digitais.
De acordo com relatório divulgado pela empresa de consultoria NewZoo, o mercado de eSports deve movimentar US$ 1,1 bilhão ao redor do mundo em 2019, com projeção para movimentar US$ 1,8 bilhão no ano de 2022.
No Brasil, os eSports também ganharam seu espaço. A Confederação Brasileira de eSports lista 13 equipes como os principais times do país em 2019. Dentre os selecionados está o braço de esportes digitais do Clube de Regatas do Flamengo, inaugurado em 2017.
A movimentação de tantos bilhões de dólares dentro do universo dos games acontece de diversas maneiras.
A principal delas é a compra dos jogos pelos jogadores, que pagam um valor para terem determinado título em uma mídia física ou em uma cópia digital obtida através de download.
Outro modelo popular é o chamado “freemium”, junção das palavras “free” (gratuito) e “ premium”. Usado principalmente em jogos mobile. Nesse cenário, o jogador consegue obter o game gratuitamente, mas precisa pagar por itens que trarão facilidades nas partidas e aprimoramentos para os personagens.
Os pacotes de DLC (“downloadable content”, ou conteúdo baixável) também se tornaram populares. Nesse modelo, o jogador paga o valor do jogo, mas também paga por conteúdos extras, como novos visuais para os personagens e novos desafios.
A publicidade nos games também é uma ferramenta usada para gerar lucro às desenvolvedoras. Usada nesse universo desde 1978, as propagandas podem aparecer através de banners que surgem na tela ou por meio do posicionamento de marcas no ambiente virtual do jogo. Em “FIFA”, franquia de simuladores de futebol, as mais diversas marcas pagam para serem inseridas nas placas de publicidade dos estádios virtuais e nas camisas dos jogadores.
Segundo a edição 2019 da Pesquisa Game Brasil, que tenta traçar o perfil dos gamers brasileiros, 66% dos brasileiros jogam videogames. Desse montante, as mulheres são maioria.

De acordo com a pesquisa, pessoas de 25 a 34 anos compõe a maior parte dos jogadores brasileiros, representando 37,7% do montante total.
A Pesquisa Game Brasil é feita a partir de uma parceria entre a agência de tecnologia Sioux Group, a empresa de pesquisa Blend New Research e a Escola Superior de Propaganda e Marketing (ESPM), levando em conta os jogos de todos os gêneros, independentemente da plataforma. Realizada anualmente, a pesquisa é feita a partir de questionário quantitativo, respondido por cerca de 3.200 pessoas.
Ainda segundo a Pesquisa Game Brasil, 67,2% dos brasileiros que jogam videogame se definiram como jogadores casuais, se envolvendo nas jogatinas até três vezes por semana, em sessões de até três horas. Cerca de 33% dos entrevistados se classificaram como jogadores hardcore, com partidas frequentes e longas.
Nos Estados Unidos, em 2017, a maior fatia do público gamer tinha entre 35 e 44 anos. 62% deles era homem e 38% era mulher.
O ato de jogar tem raízes antigas na humanidade. Em 2013, foi encontrado na Turquia o tabuleiro do jogo mais antigo que se tem conhecimento. As peças possuem pelo menos 5.000 anos.
Na terceira década do século 20, em 1938, o historiador holandês Johan Huizinga publicou o livro “Homo ludens”, peça central para os estudos dos jogos. Na obra, o autor propõe que o termo Homo ludens (o homem que joga, em tradução livre) fosse usado na nomenclatura da espécie humana, dada a importância dos jogos para o desenvolvimento das sociedades.
Também em “Homo ludens”, Huizinga apresenta a ideia do “círculo mágico”, um espaço criado a partir de uma série de premissas que fazem com que o ato de jogar seja um mergulho em outro universo, fazendo com que o jogador se distancie de suas aflições e problemas cotidianos.
Para que o “círculo mágico” seja construído, cinco premissas devem ser respeitadas:
1 – Jogar deve ser uma atividade livre, com a participação voluntária daqueles que fazem parte do jogo
2 – O jogo não deve fazer parte da vida real, construindo um universo com leis e costumes próprios
3 – O jogo precisa ter um sentido próprio, ancorado em regras que guiam a atividade para limites de tempo e espaço próprios
4 – A tensão, a incerteza e o acaso são elementos fundamentais de qualquer jogo
5 – Em todo jogo, o jogador precisa lutar por algo ou se tornar a representação de algo
Tão antigos quanto a própria cultura, os jogos atualmente ocupam um lugar de destaque no mundo do entretenimento, com os videogames sendo seus maiores expoentes, em uma crescente ao redor do mundo.
Na segunda metade do século 20, os jogos passaram a se aproveitar das tecnologias eletrônicas recentes à época para a criação de uma nova forma de entretenimento: os videogames.
O primeiro jogo eletrônico que se tem conhecimento é “Bertie the Brain”, desenvolvido em 1950 pelo engenheiro canadense Josef Kates. O título nada mais era do que uma versão em computador do clássico “Jogo da Velha”.
Porém, os anos 1970 marcaram a ascensão da popularidade e do desenvolvimento dos games. Em 1972, os fliperamas americanos passaram a oferecer “Pong” como uma opção eletrônica aos tradicionais pinballs.
Em “Pong”, dois traços, controlados pelos jogadores, precisam bater e rebater uma bolinha (quadrada), em uma versão eletrônica dos jogos de tênis de mesa.

Cinco anos depois, em 1977, os videogames chegaram aos lares americanos, com o lançamento do console Atari 2600. Desde o seu lançamento, mais de 27 milhões de unidades foram vendidas ao redor do mundo.
A partir dos anos 80, o Japão passa a ser uma potência no desenvolvimento de games. É nesta década que se estabelece uma das maiores rivalidades do mercado: a concorrência entre a Sega e a Nintendo, principais empresas da indústria de games japonesa.
A concorrência entre as duas empresas também ocupou lugar na boca dos fãs, que até hoje produzem memes e abrem discussões sobre qual das duas empresas seria melhor. Em 2018, foi anunciada a produção de uma série de TV inspirada pela disputa.
Nas primeiras duas décadas dos videogames, os jogos possuíam gráficos 2D, que traziam um visual chapado, sem qualquer noção de profundidade. Nos anos 90, os jogos 3D ganharam popularidade, com os consoles Sega Saturn e Nintendo 64. Nessa mesma década, a japonesa Sony entrou no mercado de videogames, com o lançamento do primeiro PlayStation, em 1995.
No começo dos anos 2000, a Sega abandonou o mercado de consoles após crises internas e a queda em sua popularidade. Desde então, esse setor é dominado pela Sony, pela Nintendo e pela Microsoft, que lançou, em 2001, a primeira geração do Xbox.
Algumas tendências marcaram a tecnologia dos games nos anos 2000. Em 2006, a Nintendo lançou o Nintendo Wii, console que trazia como diferencial controles sem fio que respondiam de acordo com os movimentos dos jogadores. Três anos depois, a Sony entrou na onda dos controles por movimento com o lançamento do PS Move, um controle similar ao do Wii. Em 2010, a Microsoft lançou o Kinect, uma câmera que capta os movimentos do jogador e transmite-os para os jogos, sem a necessidade de um controle físico. À época, os controles por movimento eram considerados a tecnologia que definiria o futuro dos games.
Desde 2014, a Realidade Virtual tem sido um norte para a indústria dos games, com o desenvolvimento de óculos especiais munidos de uma tela, que fazem com que o jogador fique completamente imerso no universo dos jogos que suportam esse tipo de tecnologia.
Durante todo esse processo, os jogos de computador foram se desenvolvendo de acordo com o avanço das tecnologias de computação pessoal.
Por muito tempo, os Estados Unidos e o Japão foram os maiores centros de produção e consumo de videogames no mundo.
Com o passar do tempo e a globalização, mais países emergiram dentro da indústria e passaram a ocupar a lista dos maiores mercados de videogames no mundo.
A edição 2019 do estudo da NewZoo demonstrou que os EUA são o maior país consumidor de games no mundo. China, Japão, Coreia do Sul e Alemanha completam as cinco primeiras posições, nessa ordem. O Brasil ocupa a 13ª posição do ranking.
Na Coreia do Sul, o quarto maior mercado mundial, os eSports são extremamente populares. Em 2018, o Ministério da Cultura, Esportes e Turismo do país anunciou a construção de três novas arenas para sediar eventos de esportes digitais. Entre 2014 e 2018, o governo do país investiu US$ 274 bilhões no setor.
Em 2019, 2,3 bilhões de pessoas ao redor do mundo se consideraram jogadoras de videogame, nas mais diversas plataformas. Em números de jogadores, a Ásia é o continente que representa o maior montante: 1,2 bilhão de pessoas que se consideram gamers.

Em termos de produção, a Polônia ganhou destaque nos últimos anos. O país possui cerca de 120 empresas ligadas à indústria dos games, prestando serviços em todos os estágios da produção, do desenvolvimento à distribuição.
A principal empresa no cenário é a CD Projekt, que, em 2015, ganhou o troféu Jogo do Ano do prêmio The Game Awards, o mais importante do mundo, por “The Witcher 3: Wild Hunt”. O título já vendeu mais de 20 milhões de unidades ao redor do mundo.
Na década de 2010, parte da comunidade gamer se aproximou dos discursos de direita. Dados do Facebook, publicados em janeiro de 2019, demonstraram que 34% dos gamers americanos se identificam como conservadores ou muito conservadores.
O fenômeno ganhou mais força a partir de 2014, com o surgimento do movimento Gamergate. Os membros do Gamergate se alinham com ideias misóginas, nacionalistas, xenófobas e racistas.
O britânico Milo Yiannopoulos, jornalista e ativista de extrema direita, usou o Gamergate como uma ferramenta de divulgação de suas ideias. Em 2014, no início do movimento, Yannopoulos publicou um artigo no site Breitbart onde diz que “bullies feministas estão destruindo a indústria de jogos”.
Em 2017, Steve Bannon, líder da campanha eleitoral do presidente americano Donald Trump, contou ao USA Today que Yiannopoulos soube se comunicar com os membros do movimento.
“Eu logo percebi que Milo conseguia se conectar com esses jovens”, disse Bannon. “Você pode ativar esse exército. Eles saem do Gamergate ou de qualquer coisa assim e logo começam a gostar de política e de Trump”, acrescentou.
Kristin Bezio, professora de estudos de liderança na Universidade de Richmond, acredita que o Gamergate foi um precursor da ascensão da chamada alt-right, a “direita alternativa”.
O termo alt-right inclui um grupo de indivíduos da extrema-direita que geralmente abraçam ideias nacionalistas, racistas, misóginas e antissemitas, expressadas em ambientes digitais de maneira provocativa.
Em 2011, o doutor em psicologia Andy Przybylski, da Universidade de Essex, no Reino Unido, realizou um estudo para entender por que os games se tornaram tão populares.
Os resultados foram publicados na revista Psychological Science. De acordo com Przybylski, os videogames permitem que os jogadores ajam de acordo com uma versão idealizada deles mesmos.
“A atração de se jogar um videogame, e o que os torna divertidos, é a chance que eles dão para as pessoas pensarem em um papel que elas gostariam de ter idealmente, e o fato de terem a chance de ocupar esse lugar”, afirmou.
A popularidade dos games se estendeu para além de seu próprio universo. Um fenômeno recente é a chamada gamificação. É a aplicação de mecânicas de jogos em outros campos, como a administração de empresas, a educação e a avaliação de serviços, como acontece no Uber: o sistema de estrelas do motorista e do passageiro se baseia na ideia de tarefa e recompensa, ideia central para todo jogo.
Nas escolas, os games passaram a ser usados como ferramenta de complementação do estudo. “Minecraft” é um dos jogos mais populares do mundo, permitindo que o jogador construa mundos inteiros usando bloquinhos quadrados. Em 2016, a desenvolvedora Mojang lançou uma versão do game feita especialmente para que estudantes possam pôr em prática conceitos de geografia, física e matemática.
A franquia “Assassin’s Creed” também é popular globalmente. No jogo, direcionado para um público mais velho, o jogador assume o papel de um personagem da Ordem dos Assassinos. Cada título da franquia se passa em um momento histórico diferente, do Egito Antigo à Revolução Industrial em Londres.
A partir de 2018, os jogos da franquia “Assassin’s Creed” passaram a trazer um modo educacional, sem violência, para que os jogadores explorem o momento histórico de cada título, entendendo a conjuntura sociopolítica de cada época.
Kurt Squire, doutor em Aprendizagem Conectada pela Universidade da Califórnia, publicou um artigo em 2005 onde argumenta que o uso de games dentro da sala de aula pode trazer uma motivação extra aos alunos através da fantasia, do poder de escolha, dos desafios, da competição e da curiosidade, elementos intrínsecos a qualquer jogo.
Há dentro da indústria um debate acerca da tipificação dos games enquanto uma forma de arte. Em 2012, o museu Smithsonian, um dos mais importantes do mundo, organizou uma exposição para mostrar aos visitantes os videogames enquanto expressão artística.
Em 2006, Renaud Donnedieu de Vabres, ex-Ministro da Cultura da França, afirmou que os videogames eram sim uma forma artística. Por conta disso, Vabres deu às desenvolvedoras francesas uma redução de 20% dos impostos pagos durante o processo de produção dos jogos.
No mesmo ano, Hideo Kojima, considerado um dos melhores desenvolvedores de jogos do mundo, afirmou ao site Eurogamer que não considerava os jogos uma forma de arte.
“Se 100 pessoas passam por uma obra e uma única é cativada por aquela peça, isso é arte. Mas videogames não querem cativar apenas uma pessoa. Um jogo precisa fazer com que as 100 pessoas que jogam se sintam felizes com aquele serviço”, afirmou “Os games são como um serviço. Não são arte. Mas eu acho que é a forma com que esse serviço é oferecido possui elementos artísticos”, acrescentou.
No artigo a seguir, darei a você quatro recursos de aprendizado sobre Data Science que acho que não são mencionados com tanta frequência e que pessoalmente acho extremamente úteis.

Eu não sou um cara Kaggle. Eu odeio concorrência online. Eu odeio qualquer plataforma que seja facilmente gamificada. Eu odeio ver minha classificação deslizando, minhas semanas de trabalho sendo ridicularizadas só porque alguém decidiu passar alguns minutos copiando / fazendo a média do trabalho de outras pessoas.
Mas eu aprendi muito com os principais kernels do Kaggle. Existem kernels plagiados e redundantes no Kaggle, com certeza, mas as gemas estão definitivamente lá. Você deve ter pelo menos a habilidade de pesquisar entre todas as misturas. Sobrepor os núcleos não é divertido nem útil, de forma alguma.
Alguns dos meus kernels favoritos:
O StatQuest com Josh Starmer foi absolutamente incrível para mim. Os vídeos dele foram as coisas mais densas em termos de informação, mas divertidas que já encontrei – a maioria dos vídeos é curta (cerca de 5 a 8 minutos), ao mesmo tempo em que é informativa e hilária. Caso você fique preso em um tópico ou não consiga entendê-lo, a explicação gráfica do StatQuest pode ser seu salvador. O canal possui vídeos sobre Machine Learning e Estatística em R e Python.
Não é a Khan Academy, mas alguns livros didáticos de 1000 páginas? Sim, você ouviu direito. Na minha opinião, nada se compara à educação universitária se você quiser REALMENTE estudar matemática (neste contexto: cálculo, álgebra linear).

Conheço muitas pessoas que apenas fizeram cursos on-line ou leram algum material, mas fracassariam miseravelmente se recebessem um exame – isso é porque há muito menos pressão para realmente aprender a matemática envolvida em comparação com o estudo de matemática na faculdade. Aqui está o que eu passei nas aulas de matemática na faculdade: dever de casa e teste na aula todas as semanas, que são contados para a sua nota final, um grande exame a cada 1-2 meses que corresponde a 30% da sua nota geral e uma tonelada de pressão para aprender ao longo do semestre.
Como você deve se ensinar matemática, então? Obtenha um livro da universidade sobre álgebra / cálculo linear e faça os exercícios. Em seguida, faça um exame ou vários exames dos últimos anos em uma universidade e faça-os até conseguir passar em um exame sem olhar para a folha de respostas ou ser gentil ao se corrigir. Pratique, pratique, pratique em exercícios cada vez mais difíceis até conseguir um A.
Por artigos online, quero dizer curto, direto ao ponto. Se você acha difícil ler artigos longos de pesquisa, essa opção pode ser para você. O mesmo com o Kaggle Kernels, você encontrará muitos artigos preguiçosos e plagiados na Internet. Ao pesquisar um tópico, você precisa ter um objetivo específico em mente, porque é muito fácil ficar de fora de qualquer link atraente que você vê na página de Pesquisa do Google.

Afinal, não os recursos, mas o que você aprendeu é o que importa. Os cientistas de dados estão naturalmente curiosos sobre os dados que estão visualizando. Tente conectar os pontos .
Fonte: Medium
A CNN noticiou que o computador mais potente do mundo — o Summit, da IBM — acabou de apontar 77 drogas promissoras contra o novo coronavírus.
A notícia é boa sob muitos aspectos. Sobretudo, porque mostra que a Inteligência Artificial – IA, se utilizada para propósitos corretos, pode converter-se numa ferramenta incrível no combate rápido e eficaz de doenças infecciosas, mas não só delas.
Depois, porque é ilustrativa de como se dará, nos próximos anos e décadas, o progresso com o uso da IA. Realmente, a implementação da IA para resolver problemas práticos sustenta-se em três pilares:
1) dados sobre os fatos que se quer trabalhar (no caso, sobre as drogas e sobre as doenças que elas tratam e sua eficácia);
2) capacidade de computação, isto é, de manipulação dos dados por um processador (no caso, o Summit é o computador mais poderoso do mundo);
3) algoritmos fortes, ou seja, programas de instrução ao computador concebidos com precisão e criatividade.
Cada um desses fundamentos está se desenvolvendo de modo rápido e independente. Os dados têm tido um crescimento orgânico exponencial no nosso dia a dia. A vida está se tornando cada vez mais digitalizada, desde a compra de um remédio, a uma conversa com um amigo, a um deslocamento pela cidade, etc,, tudo aquilo que fazemos está de algum modo se convertendo em dados que acabam, de algum modo, caindo na internet.
A capacidade de computação também não para de crescer. Segundo a Lei de Moore, formulada em 1965 e ainda válida até certo ponto, a cada 18 meses essa capacidade dobra de tamanho (isso para não falar na computação quântica, que se vier a se tornar realidade, irá acelerar de modo dramático esse crescimento). E, finalmente, os algoritmos. Esses são a face mais brilhante dessa evolução.
Os algoritmos estão apoiados sobre conhecimentos matemáticos. Eles são como uma tradução, em termos rigorosos, de um acontecimento do mundo. Nesse aspecto, eles mimetizam a inteligência humana.
Percebemos o mundo pelos sentidos, e com esses “dados” e “experiências anteriores” nossos cérebros criam conhecimento, que é essencialmente previsão. Aqui há muita discussão filosófica sobre se o conhecimento é prévio à experiência, se nasce apenas dela, ou de um mix de formas mentais apriorísticas em contato com o mundo sensível.
Em todo caso, parece certo que a experiência desempenha papel importante, e é fora de dúvida que está no cérebro a capacidade de sintetizar os dados caóticos para construir o conhecimento. Mas muitas perguntas desconcertantes remanescem: como se dá essa síntese? O amontado de impulsos elétricos se transforma em conhecimento de uma forma rígida ou também a forma de sintetizar muda? O que é, afinal, o conhecimento?
Sem querer dar respostas para essas complexas indagações, e nos concentrando apenas no chamado “conhecimento científico”, podemos avançar um pouco, admitindo que esse tipo de pensamento está enraizado na ideia de “causalidade”.
Especialmente para as chamadas ciências empíricas, a ligação de causa e efeito está na base da produção do conhecimento. Se aumento a temperatura de um gás, então o seu volume aumenta; se solto um corpo de certa altura na Terra, ele cai a uma aceleração próxima de 10m/s2, etc. — essas são premissas científicas que foram construídas com base em observação e síntese intelectual.
É problemático dizer que a causalidade está na Natureza, e não em nossa forma de vê-la. Basta pensar nas “descobertas” que nos fizeram ver coisas que antes não víamos.
Ora, se isso acontece o tempo todo, então é razoável supor que há ainda um vasto número de causalidades desconhecidas e que, mesmo sobre o que sabemos, podemos depois construir um conhecimento mais correto, com mais observações e mais trabalho intelectual. Santo Agostinho dizia que o milagre existe e não nega a causalidade, pois ele apenas revela aspectos que não sabemos sobre a causalidade.
A causalidade, quando entra na linguagem, converte-se numa conexão de sentido estabelecida entre duas ou mais informações: dado o fato A, então ocorre (ou deve ocorrer) o fato B. Nosso cérebro aprende esse tipo de ligação ora com a experiência, ora com o ensino orientado. Ele também é capaz de cruzar muitas dessas causalidades e inferir outras, eventualmente nunca “experienciadas”.
Aí estamos no campo do insight, que é a percepção de uma causalidade oculta e surpreendente. Praticamente, é um insight que os cientistas buscam ao apresentar ao Summit o problema da proliferação do COVID19.
As máquinas, a princípio, eram limitadas quanto a oferecer respostas novas para problemas velhos ou não previamente conhecidos. Isso porque elas já nasciam prontas, não “aprendiam” nada. Arthur Samuel, em 1959, foi um dos primeiros a usar o termo aprendizado de máquina (machine learning) num artigo em que discutia a possibilidade de um computador “aprender” a jogar damas melhor do que o seu programador.
Ou seja, se seria possível que a máquina fizesse uma atividade sem ter sido explicitamente programada para tal. Essa revolução só poderia ocorrer com alterações nos algoritmos, o que acabou ocorrendo nas décadas seguintes.
O ponto central do machine learning é a capacidade de autoaprendizado com base em um conjunto de dados. Em vez de o input exprimir um comando para gerar o output pré-programado, no machine learning o input é o próprio conjunto de dados brutos, que será tratado por um modelo que produzirá o output, segundo relações de inferência estatística e outros métodos de cálculo matemático.
Isso quer dizer que o output não é previamente conhecido sequer do programador, pois depende do conjunto de dados apresentado, do algoritmo utilizado e até das “experiências anteriores” do algoritmo.
De fato, uma característica importante do machine learning é a sua capacidade de aperfeiçoamento com a “experiência”. À medida que o modelo é mais e mais treinado com diferentes conjuntos de dados, os outputs tendem a apresentar mais acurácia. Nas rígidas programações pré-definidas, isso não ocorre, pois, o programa não evolui.
Os vírus, por outro lado, são criaturas impressionantes, que têm uma habilidade específica para ocupar organismos vivos (seria isso uma forma de inteligência?). Não há consenso sequer sobre se eles são seres vivos ou não, embora não haja dúvida sobre quanto dano eles são capazes de causar.
Com uma notável capacidade de adaptação às mais diferentes condições, seu parco material genético (digamos, seu algoritmo), seu minúsculo tamanho (digamos, seu hardware), os vírus são uma antiga e poderosa força bruta da natureza, capazes de infectar até mesmo bactérias.
Sou tecno-otimista. Acho que Summit versus Corona é o modelo de uma luta que promete ser cada vez mais favorável para nós, humanos. As “máquinas pensantes” podem abrir novos horizontes, com mais qualidade de vida, mais longevidade e mais desenvolvimento humano de um modo geral.


We all know that it can be hard sometimes to find new application ideas that you could build in order to either improve or learn a new programming language or framework.
Tip: When writing reusable code, turn into Bit components. Then you can easily share and reuse it across all your apps and projects, to easily build better modular software applications faster. It’s open source, give it a try.
In this article we’re going to look into 15 app ideas which are:
And on top of that, each app idea has:
We divided these app ideas into three tiers based on the knowledge and experience required to complete them. The tiers are: Beginner, Intermediate and Advanced.
In this article you’ll find 5 ideas from each tier.
Tier: 1-Beginner
We all have important events we look forward to in life, birthdays, anniversaries, and holidays to name a few. Wouldn’t it be nice to have an app that counts down the months, days, hours, minutes, and seconds to an event? Countdown Timer is just that app!
The objective of Countdown Timer is to provide a continuously decrementing display of the he months, days, hours, minutes, and seconds to a user entered event.
clearInterval MDNsetInterval MDNCountdown Timer built with React
Tier: 1-Beginner
It’s important for Web Developers to understand the basics of manipulating images since rich web applications rely on images to add value to the user interface and user experience (UI/UX).
FlipImage explores one aspect of image manipulation — image rotation. This app displays a square pane containing a single image presented in a 2×2 matrix. Using a set of up, down, left, and right arrows adjacent to each of the images the user may flip them vertically or horizontally.
You must only use native HTML, CSS, and Javascript to implement this app. Image packages and libraries are not allowed.
Tier: 1-Beginner
Create and store your notes for later purpose!
Markdown Notes built with Angular on Codepen
Markdown Notes built with React
Markdown Notes built with Angular 7 and bootstrap 4
Tier: 1-Beginner
You might not have realized this, but recipe’s are nothing more than culinary algorithms. Like programs, recipe’s are a series of imperative steps which, if followed correctly, result in a tasty dish.
The objective of the Recipe app is to help the user manage recipes in a way that will make them easy to follow.
Recipe Box — a Free Code Camp Project (FCC)
Tier: 1-Beginner
Practice and test your knowledge by answering questions in a quiz application.
As a developer you can create a quiz application for testing coding skills of other developers. (HTML, CSS, JavaScript, Python, PHP, etc…)
buttonpassed or failed the quizQuiz app built with React (wait for it to load as it is hosted on Heroku)
Tier: 2-Intermediate
Create an application that will allow users to search for books by entering a query (Title, Author, etc). Display the resulting books in a list on the page with all the corresponding data.
input fieldYou can use the Google Books API
Tier: 2-Intermediate
Card memory is a game where you have to click on a card to see what image is underneath it and try to find the matching image underneath the other cards.
n is an integer). All the cards are faced down initially (hidden state)visible state). The image will be displayed until the user clicks on a 2nd cardWhen the User clicks on the 2nd card:
visible state)hidden state)Tier: 2-Intermediate
Create digital artwork on a canvas on the web to share online and also export as images.
canvas using the mousecanvas.png, .jpg, etc format)rectangle, circle, star, etc)Tier: 2-Intermediate
The goal of the Simple Online Store is to give your users the capability of selecting a product to purchase, viewing purchase information, adding it to an online shopping cart, and finally, actually purchasing the products in the shopping cart.
There are plenty of eCommerce Site Pages out there. You can use Dribbble and Behance for inspiration.
Tier: 2-Intermediate
The classic To-Do application where a user can write down all the things he wants to accomplish.
input field where he can type in a to-do itemcompletedTier: 3-Advanced
Getting and staying healthy requires a combination of mental balance, exercise, and nutrition. The goal of the Calorie Counter app is to help the user address nutritional needs by counting calories for various foods.
This app provides the number of calories based on the result of a user search for a type of food. The U.S. Department of Agriculture MyPyramid Food Raw Data will be searched to determine the calorie values.
Calorie Counter also provides you, the developer, with experience in transforming raw data into a format that will make it easier to search. In this case, the MyPyramid Food Raw Data file, which is an MS Excel spreadsheet, must be downloaded and transformed into a JSON file that will be easier to load and search at runtime (hint: take a look at the CSV file format).
Tier: 3-Advanced
Real-time chat interface where multiple users can interact with each other by sending messages.
As a MVP(Minimum Viable Product) you can focus on building the Chat interface. Real-time functionality can be added later (the bonus features).
input field where he can type a new messageenter key or by clicking on the send button the text will be displayed in the chat box alongside his username (e.g. John Doe: Hello World!)channels on specific topicsTier: 3-Advanced
API’s and graphical representation of information are hallmarks of modern web applications. GitHub Timeline combines the two to create a visual history of a users GitHub activity.
The goal of GitHub Timeline is accept a GitHub user name and produce a timeline containing each repo and annotated with the repo names, the date they were created, and their descriptions. The timeline should be one that could be shared with a prospective employer. It should be easy to read and make effective use of color and typography.
Only public GitHub repos should be displayed.
GitHub offers two API’s you may use to access repo data. You may also choose to use an NPM package to access the GitHub API.
Documentation for the GitHub API can be found at:
Sample code showing how to use the GitHub API’s are:
You can use this CURL command to see the JSON returned by the V3 REST API for your repos:
curl -u "user-id" https://api.github.com/users/user-id/repos
Building a Vertical Timeline With CSS and a Touch of JavaScript
Tier: 3-Advanced
As a Web Developer you’ll be asked to come up with innovative applications that solve real world problems for real people. But something you’ll quickly learn is that no matter how many wonderful features you pack into an app users won’t use it if it isn’t performant. In other words, there is a direct link between how an app performs and whether users perceive it as usable.
The objective of the Shuffle Card Deck app is to find the fastest technique for shuffling a deck of cards you can use in game apps you create. But, more important it will provide you with experience at measuring and evaluating app performance.
Your task is to implement the performance evaluation algorithm, the Xorshift pseudorandom number generator, as well as the WELL512a.c algorithm if you choose to attempt the bonus feature.
Tier: 3-Advanced
Surveys are a valuable part of any developers toolbox. They are useful for getting feedback from your users on a variety of topics including application satisfaction, requirements, upcoming needs, issues, priorities, and just plain aggravations to name a few.
The Survey app gives you the opportunity to learn by developing a full-featured app that you can add to your toolbox. It provides the ability to define a survey, allow users to respond within a predefined timeframe, and tabulate and present results.
Users of this app are divided into two distinct roles, each having different requirements:
Commercial survey tools include distribution functionality that mass emails surveys to Survey Respondents. For simplicity, this app assumes that surveys open for responses will be accessed from the app’s web page.
Libraries for building surveys:
Some commercial survey services include:
Now you have a basis of 15 applications that you can play with. We created a GitHub repository where you can find even more ideas if you are interested and you are welcomed to contribute, share and give it a star!
By Wired

Tânia Cosentino, da Microsoft Brasil: falta de mão de obra especializada no país preocupa executivos (Alan Teixeira/Divulgação)
O Brasil está fadado a fracassar na disputa pelo posto de liderança em inteligência artificial. De acordo com Tânia Cosentino, CEO da Microsoft Brasil, isso deve ocorrer em função da baixo interesse dos brasileiros por matemática.
“No índice de pessoas graduadas [no Brasil], somente 15% são da área de exatas, enquanto a China está beirando os 40%. Vamos perder a batalha da inteligência artificial”, afirmou a executiva, durante evento do BTG Pactual (controlador de EXAME). Ela também chama a atenção para a pequena participação feminina no segmento. “Desses 15%, somente 15% são mulheres.”
A baixa qualificação da mão de obra brasileira em tecnologia é uma das principais preocupações dos executivos da área. “Hoje, skills [qualificação] é o tema central”, afirmou o CEO da IBM Brasil. Segundo ele, o número de vagas com carência de mão de obra qualificada no Brasil deve chegar a 500 mil nos próximos cinco anos.
Para Cosentino, a demanda por esse tipo de profissional vai aumentar de forma que não vai dar tempo para as pessoas se especializarem. “Ao contrário da terceira revolução industrial, que demorou 30 anos, isso vai acontecer em menos de 10 anos. Vir para a nossa área é emprego garantido”, disse.
Fonte: Exame

Se você anda procurando um framework para construir aplicativos para dispositivos móveis que funcione tanto no Android como no iOs, você deve dar um pouco de atenção ao Flutter.
O Flutter é um UI Toolkit , ou seja, um kit de ferramentas de interface do usuário, que fornece uma série de componentes visuais e funcionais para o desenvolvimento de aplicativos híbridos (que rodam em qualquer sistema operacional).
No finzinho de 2018 o Google anunciou a primeira Release do Flutter através do blog Google Developers. Mas ele já vinha sendo utilizado por desenvolvedores do mundo inteiro desde o início de 2018. O framework promete desenvolvimento rápido e pouco verboso (você vai escrever menos). Além disso, segundo o que consta no próprio site do Flutter, ele promete ter a performance de aplicativos nativos.
O Google afirma que o Flutter não pode substituir completamente o modelo tradicional de construção de aplicativos para iOS ou Android. Mas que na verdade é um engine que pode ser adicionado a apps existentes, ou então ser usado na construção de aplicativos inteiros.
As características do Flutter, segundo o próprio Google, são:
– O Flutter possibilita que você faça aplicativos bonitos. O framework dá ao desenvolvedor a liberdade de modificar cada pixel da tela. O objetivo é dar liberdade aos designers para usem sua criatividade sem que percam parte de seu trabalho por causa de limitações técnicas. Além disso, é possível usar o Material Design do Google, com uma gama de Widgets já disponíveis. Para iOS, se você preferir, pode usar o Cupertino sem nenhuma dificuldade. É claro que deixar um app bonito depende muito da criatividade do designer, mas o Flutter fornece ferramentas que podem ajudar.
– O Flutter é rápido. Ele é alimentado pelo mesmo mecanismo que acelera o Chrome e o Android: o Skia 2D. Esse mecanismo foca na aceleração de hardware, é mantido pelo Google, mas é open source e é usado por diversos outros softwares como Firefox e Firefox OS. A promessa do Google é de que a arquitetura do Flutter foi projetada para suportar gráficos jank-free na velocidade do dispositivo. Além disso, os aplicativos feitos com Flutter, são escritos na linguagem de programação Dart. Os apps escritos nessa linguagem podem ser compilados para nativos do Android ou do iOS com processadores ARM de 32 ou 64 bits. Isso é o que torna o Flutter rápido.
– O Fluter é produtivo. O Flutter permite que você execute o aplicativo em um smartphone ou emulador enquanto programa. Toda vez que você salvar um arquivo no projeto, o aplicativo vai atualizar automaticamente no dispositivo, de maneira incrivelmente rápida. É o que os desenvolvedores chamam de stateful hot reload. Segundo o Google, essa funcionalidade a forma com a qual os desenvolvedores constroem aplicativos, tornando o processo mais produtivo.
– E por fim, é livre, é aberto. O Flutter é um projeto open source com a licensa BSD-style, incluindo contribuições de centenas de desenvolvedores no mundo inteiro. O projeto está disponível no GitHub, assim como as instruções de como contribuir.
Bom, se você procura por agilidade no desenvolvimento, e UIs bonitas, o Flutter é uma boa opção, além de ter uma performance muito boa quando comparado a concorrentes, como o Ionic por exemplo.
O Flutter te dá liberdade em muita coisa, da arquitetura e organização do projeto até a interface do usuário. Ele deixa você trabalhar do jeito que achar melhor, e ainda dá suporte a todas as funcionalidades nativas do Android ou do iOS.
A comunidade do Flutter está crescendo a cada dia, e já é possível encontrar templates prontos, issues resolvidas no GitHub ou em outros fóruns. Além da linguagem (Dart) ser relativamente fácil, se você é acostumado com JavaScript, vai conseguir caminhar em pouco tempo.

Para ter uma ideia de o quanto e como o flutter é usado, é só dar uma olhada na página de showcase deles (imagem acima). Além de tantos outros apps incríveis que são desenvolvidos e lançados pelo mundo a fora e não estão na lista.
Fonte: Clube dos Geeks06

Para analisar se o Brasil está preparado para alcançar os potenciais benefícios trazidos pela Inteligência artificial, a consultoria americana DuckerFrontier, a pedido da Microsoft, elaborou o Índice de Preparação para a IA (AI Readiness Index), um indicador que cruza as variáveis de desenvolvimento e disseminação da IA e une todos os fatores relacionados à sua implementação. Na análise, foram considerados sete países da América Latina: Brasil, México, Chile, Colômbia, Peru, Argentina e Costa Rica.
De acordo com o índice, o Brasil está em uma posição que pode melhorar para acelerar a adoção de IA em relação à outros países na região, como o Chile, o México, e a Colômbia, conforme mostra o pilar de “Desenvolvimento e Disseminação de IA” do índice. Neste pilar, o Brasil está bem posicionado nos quesitos cibersegurança e ecossistema tecnológico, figurando na segunda posição em ambos. Já em capital humano e ambiente de inovação, o país está em posição desfavorável, ocupando o 7º e o 6º lugares, respectivamente.
O estudo destaca ainda cinco categorias que deveriam ser priorizadas para o desenvolvimento de IA no país: governo, serviços públicos e governança; educação, habilidades e capacitação; pesquisa, inovação e desenvolvimento; infraestrutura de tecnologia; e ética, regulamentação e legislação. É citado como exemplo a necessidade de um amplo compromisso do governo em liderar o desenvolvimento de uma estratégia nacional de IA aliado com o envolvimento do setor privado, da academia e da sociedade civil.
Alguns passos previstos na pesquisa para que o governo prepare o país para essa transformação de forma ética, transparente e com um impacto positivo na sociedade são investir no poder da computação em nuvem, criação de um banco de dados nacional para uso público e privado, criação de um Centro Nacional de Pesquisa em Inteligência Artificial, uso de IA na prestação de serviços públicos, inclusão de habilidades relevantes para a IA no sistema educacional como inteligência computacional e treinamento digital para servidores públicos. Além disso, o estudo também faz recomendações para fomentar a participação de mulheres em carreiras de tecnologia e estímulo a startups.
O levantamento foi divulgado na segunda edição do AI + Tour, evento da Microsoft que percorre oito países da América Latina, incluindo o Brasil, para apresentar como a Inteligência Artificial (IA) já é uma das principais alavancas de transformação digital e o potencial da IA no futuro dos negócios e da sociedade.
Com uma apresentação sobre como a evolução da IA vai modificar a sociedade em que vivemos, Tim O’Brien, diretor geral de programas de IA da Microsoft, ressaltou a importância de desenvolver essa tecnologia de forma transparente, ética e responsável. “A IA tem potencial para nos ajudar a resolver alguns dos maiores desafios do mundo. A oportunidade é significativa, mas o design, o desenvolvimento e o uso responsáveis são igualmente importantes. A tecnologia e as ciências sociais devem andar lado a lado para garantir um impacto positivo nas pessoas e na sociedade”, diz O’Brien.
As simulações, que consideram as áreas de serviços públicos, prestação de serviços corporativos, comércio varejista, atacadista, hotelaria e alimentação, construção, manufatura, mineração, água e energia, e agricultura e pesca, mostram que a adoção máxima de IA no país pode aumentar a taxa composta anual de crescimento (CAGR) do Produto Interno Bruto (PIB) para 7,1% ao ano até 2030, considerando um cenário de máximo impacto pelos benefícios da IA. Esse é um aumento superior à projeção de 2,9% de crescimento do PIB feita pelo Banco Mundial e pelo Fundo Monetário Internacional (FMI) no mesmo período.
Segundo o estudo, o maior avanço do PIB viria acompanhado ainda de um crescimento até quatro vezes maior nos níveis de produtividade do país, podendo chegar a uma taxa composta anual de crescimento de até 7% ao ano no período até 2030, comparada a 1,7% de crescimento ao ano estimado pelo Banco Mundial e pelo FMI.
Fonte: Convergência Digital

TECNOLOGIA POSSIBILITA CHECAR FOTOS, MAS AINDA NÃO CONSEGUE EXAMINAR VÍDEOS
Entre as muitas informações falsas que circularam durante as eleições de 2018, a maior parte trazia imagens como “prova”. Por exemplo, as fotografias de boletins de urnas que mostravam o candidato Fernando Haddad com quase 10 mil votos enquanto Jair Bolsonaro tinha zero votos, indicando uma suposta fraude eleitoral.
Uma nova ferramenta anunciada nos Estados Unidos junta diversas tecnologias desenvolvidas em diferentes centros de pesquisa para tornar mais eficiente a detecção de imagens manipuladas. Segundo a Jigsaw, uma incubadora de tecnologia do Google, trata-se de uma solução “avançada” para um mundo em que a criação de conteúdo enganoso é cada vez mais sofisticada.
A iniciativa se chama Assembler. Segundo o texto de apresentação, existem muitas ferramentas que conseguem examinar um aspecto específico de uma imagem, mas que têm alcance limitado por causa disso.
Por exemplo: o software que percebe nuances de brilho que podem indicar uma sobreposição de imagens não consegue captar inconsistências em grupos de pixels (um pixel é a menor unidade de uma imagem; uma fotografia é formada por milhares ou milhões de pixels).
O projeto da Jigsaw reúne as capacidades de sete desenvolvedores diferentes, compondo um “kit de análise” bem mais completo. O Assembler ainda está em fase de testes, realizados com organizações jornalísticas em diferentes países. A empresa não planeja disponibilizar a ferramenta para o público.
Uma das ferramentas incluídas no projeto é um programa que detecta o uso na imagem de uma tecnologia de deepfake chamada StyleGAN. Essa tecnologia usa a inteligência artificial para gerar novos rostos humanos a partir de características de rostos de pessoas existentes. Os resultados são realistas ao extremo.
Outro recurso incorporado no Assembler é um algoritmo que analisa os “patches” (grupos de pixels) de uma imagem para determinar se algum deles foi copiado e colado em outra parte da foto, com o objetivo de cobrir algum elemento que se desejava remover.

IMAGEM MANIPULADA SIMULA ENCONTRO DO EX-PRESIDENTE AMERICANO BARACK OBAMA COM O PRESIDENTE DO IRÃ, HASSAN ROUHANI
Diferenças de contraste ou divisões pouco naturais são o alvo de outra tecnologia que faz parte da iniciativa de checagem do Google. Nesse caso, a inteligência artificial se vale dos valores cromáticos da imagem, ou seja, os graus de luminosidade ou escuridão encontrados.
O projeto consegue dar conta de algumas das técnicas existentes para modificação de fotos, mas não de todas. Ele também, inicialmente, existe como plataforma separada de redes sociais como o Facebook, local de intensa circulação de conteúdo fake.
Outra limitação é que esse tipo de análise ainda não pode ser realizada em conteúdo de vídeo. Atualmente, a manipulação de imagens em movimento é a “vanguarda” do conteúdo fraudulento das deepfakes. Em 2019, um vídeo que coloca frases na boca do fundador do Facebook, Mark Zuckerberg, evidenciou o nível de sofisticação disponível atualmente.
Outra categoria de deepfake, em que um rosto é enxertado em outro corpo, são motivo de preocupação do Departamento de Defesa dos Estados Unidos desde 2018. O órgão criou um software de análise de vídeos que consegue detectar pistas sutis em imagens manipuladas.
Fonte: Nexo Jornal

Você provavelmente já ouviu falar de Machine Learning e inteligência artificial , mas tem certeza de que sabe o que são? Se você está lutando para entendê-las, não está sozinho. Há muita agitação que torna difícil dizer o que é ciência e o que é ficção científica. Começando com os próprios nomes…
Graças às novas tecnologias computacionais, o machine learning de hoje não é como o machine learning do passado. Ele nasceu do reconhecimento de padrões e da teoria de que computadores podem aprender sem serem programados para realizar tarefas específicas; pesquisadores interessados em inteligência artificial queriam saber se as máquinas poderiam aprender com dados.
O aspecto iterativo do Machine Learning é importante porque, quando os modelos são expostos a novos dados, eles são capazes de se adaptar independentemente. Eles aprendem com computações anteriores para produzir decisões e resultados confiáveis, passíveis de repetição. Isso não é uma ciência nova – mas uma ciência que está ganhando um novo impulso.
Ao contrário da crença popular, o Machine Learning não é uma caixa mágica de mágica, nem é o motivo de US $ 30 bilhões em financiamento de VC. Na sua essência, o aprendizado de máquina é apenas um rotulador de coisas , pegando sua descrição de algo e dizendo qual rótulo ele deve receber.
O que parece muito menos interessante do que você lê no Hacker News. Mas você ficaria empolgado o suficiente para ler sobre esse tópico se o chamamos de rotulagem de coisas em primeiro lugar? Provavelmente não, o que mostra que um pouco de marketing e deslumbramento podem ser úteis para obter dessa tecnologia a atenção que ela merece (embora não seja pelas razões que você imagina).
E a inteligência artificial (IA)? Enquanto os acadêmicos discutem sobre as nuances do que a IA é ou não , a indústria está usando o termo para se referir a um tipo específico de Machine Learning. De fato, na maioria das vezes as pessoas as usam de forma intercambiável, e eu posso viver com isso. Então, a IA também é sobre rotulagem de coisas.
Você estava esperando robôs ? Algo de ficção científica com uma mente própria, algo humanóide? Bem, a IA de hoje não é isso. Mas somos uma espécie que vê traços humanos em tudo. Vemos rostos em torradas, corpos em nuvens, e se eu costurar dois botões em uma meia, posso acabar falando com ela. Esse fantoche de meia não é uma pessoa, e nem a IA – é importante ter isso em mente. Isso é uma decepção? Queixo para cima! A coisa real é muito mais útil.
Deixe-me mostrar por que você deveria estar animado. O que você vê na foto?

Que tipo de animal é esse? Calma, né? Agora me diga o que seu cérebro fez com esses pixels para obter essa resposta.
Você acabou de captar alguns dados bastante complexos através de seus sentidos e, como se por mágica, você o rotulou de ‘gato’. Isso foi tão fácil para você! Que tal se quiséssemos que um computador fizesse a mesma tarefa, classificasse (rotulasse) as fotos como gato / não gato?
Na abordagem tradicional de programação, um programador pensaria muito sobre os pixels e os rótulos, se comunicaria com o universo, inspiraria os canais e, finalmente, criaria um modelo. Um modelo é apenas uma palavra chique para receita ou um conjunto de instruções que seu computador precisa seguir para transformar pixels em etiquetas.
Um modelo é uma receita que um computador usa para transformar dados em etiquetas. São apenas alguns códigos que a máquina usa para converter entradas em saídas e podem ser artesanais por um programador ou aprendidos com os dados por um algoritmo.
Mas pense sobre quais seriam essas instruções. O que você está realmente fazendo com esses pixels? Você pode expressar isso? Seu cérebro teve o benefício de eras da evolução e agora simplesmente funciona, você nem sabe como funciona. Essa receita é bem difícil de encontrar.
Não seria melhor se você pudesse simplesmente dizer ao computador: “Aqui, veja vários exemplos de gatos, veja vários exemplos de não-gatos e descubra você mesmo”? Essa é a essência do Machine Learning. É um paradigma de programação completamente diferente.
Agora, em vez de fornecer instruções explícitas, você programa com exemplos e o algoritmo de Machine Learning encontra padrões nos seus dados e os transforma nessas instruções que você não poderia escrever por conta própria. Não há mais artesanato de receitas!
Por que isso é emocionante? Trata-se de expressar nossos desejos aos computadores de uma maneira que não podíamos antes. Adoramos fazer com que os computadores façam coisas para nós. Mas como podemos dar instruções se as instruções são realmente difíceis de pensar? Se eles são inefáveis?
IA e Machine Learning são sobre como automatizar o indescritível. Eles se explicam usando exemplos em vez de instruções. Isso desbloqueia uma enorme classe de tarefas com as quais não conseguimos obter computadores para nos ajudar no passado, porque não conseguimos expressar as instruções. Agora todas essas tarefas se tornam possíveis – o Machine Learning representa um salto fundamental no progresso humano. É o futuro e o futuro está aqui!
Graças às novas tecnologias computacionais, o machine learning de hoje não é como o machine learning do passado. Ele nasceu do reconhecimento de padrões e da teoria de que computadores podem aprender sem serem programados para realizar tarefas específicas; pesquisadores interessados em inteligência artificial queriam saber se as máquinas poderiam aprender com dados.
O aspecto iterativo do Machine Learning é importante porque, quando os modelos são expostos a novos dados, eles são capazes de se adaptar independentemente. Eles aprendem com computações anteriores para produzir decisões e resultados confiáveis, passíveis de repetição. Isso não é uma ciência nova – mas uma ciência que está ganhando um novo impulso.
Embora diversos algoritmos de machine learning existam há muito tempo, a capacidade de aplicar cálculos matemáticos complexos ao big data automaticamente – de novo e de novo, mais rápido e mais rápido – é um desenvolvimento recente. Eis alguns exemplos bem conhecidos de aplicações de machine learning, dos quais você já deve ter ouvido falar:
O interesse renovado no Machine Learning se deve aos mesmos fatores que tornaram a mineração de dados e a análise Bayesiana mais populares do que nunca: coisas como os crescentes volume e variedade de dados disponíveis, o processamento computacional mais barato e poderoso, o armazenamento de dados acessível etc.
Tudo isso significa que é possível produzir, rápida e automaticamente, modelos capazes de analisar dados maiores e mais complexos, e entregar resultados mais rápidos e precisos – mesmo em grande escala. E ao construir modelos precisos, uma organização tem mais chances de identificar oportunidades lucrativas – ou de evitar riscos desconhecidos.
Fonte: Wired e Blog SAS
Existem muitas habilidades técnicas que um engenheiro de software deve dominar, mas outras apenas com a experiência do dia a dia no mercado de trabalho podem desenvolver. Vamos te dizer sete delas para você se tornar um profissional ainda mais preparado.
É uma grande habilidade, que possui vários benefícios, poder seguir o código de outras pessoas.
Não importa o quão confuso ou mal pensado seja o código de um engenheiro anterior, você ainda precisa ser capaz de percorrê-lo. Afinal, é o seu trabalho. Mesmo quando você era esse engenheiro um ano antes.
Essa habilidade o beneficia de duas maneiras. Por um lado, poder ler o código de outras pessoas é uma ótima chance de aprender o que é um design ruim. Enquanto você olha o código de outras pessoas, aprende o que funciona e o que não funciona. Mais importante, você aprende que tipo de código é fácil para outro engenheiro seguir e que código é difícil de seguir.
Você precisa garantir o máximo possível de leitura ao ler o código de outras pessoas. Dessa forma, outros engenheiros entendem o quanto você é um engenheiro superior.
Lembre-se de mencionar a importância do código de manutenção e bons comentários. Isso mostra ainda mais seu domínio na área de programação.
Seu código deve ser tão bem projetado que não requer documentação. De fato, você não deve documentar nenhum código, se for um bom programador. Isso é apenas uma perda de tempo e você precisa gastar seu tempo codificando e em reuniões.
Ser capaz de ler o código confuso de outras pessoas também facilita a atualização quando necessário. Ocasionalmente, isso significa atualizar o código em que você não possui experiência. Por exemplo, uma vez seguimos um script de Powershell a Python e Perl. Tínhamos experiência limitada em Perl, mas ainda tínhamos contexto suficiente para descobrir o que estava acontecendo e fazer as alterações necessárias.
Isso ocorre por ter um entendimento decente de todo o código, além de poder ler os scripts Perl. A leitura do código de outras pessoas o torna valioso porque você pode seguir até sistemas com engenharia excessiva que podem surpreender os outros.
Existem muitas habilidades que levam tempo para aprender. Uma das habilidades que acreditamos que vale a pena conhecer é entender quais projetos não valem a pena ser realizados e quais são claramente marchas da morte.
As grandes empresas sempre têm muito mais projetos em andamento do que provavelmente jamais serão concluídos ou impactantes. Existem alguns projetos que podem não fazer sentido nos negócios (pelo menos não para você) e outros que são mal gerenciados. Isso não quer dizer que você deva interromper uma ideia quando discordar do projeto. No entanto, se as partes interessadas não puderem explicar adequadamente o que farão com o resultado final, talvez o projeto não valha a pena.
Além disso, alguns projetos podem ser tão focados na tecnologia em vez da solução que pode ficar claro desde o início que não haverá muito impacto. Essa habilidade requer muitos projetos ruins antes que você tenha uma idéia do que realmente é um projeto ruim. Portanto, não gaste muito tempo cedo tentando discernir cada projeto.
Em algum momento de sua carreira, você terá apenas um bom senso.
Seja você um engenheiro de software ou cientista de dados, as reuniões são uma necessidade, porque você precisa estar na mesma página com seus gerentes de projeto, usuários finais e clientes. No entanto, também há uma tendência para as reuniões assumirem repentinamente toda a sua agenda. É por isso que é importante aprender a evitar reuniões desnecessárias. Talvez uma palavra melhor para usar seja gerenciar e não evitar. O objetivo aqui é garantir que você gaste seu tempo em reuniões que conduzam decisões e ajudam sua equipe a seguir em frente.
O método mais comum é simplesmente bloquear um bloqueio de duas horas todos os dias, que é uma reunião constante. Geralmente, a maioria das pessoas marca uma reunião recorrente em um momento que considera benéfico. Eles usarão isso como um tempo para acompanhar seu trabalho de desenvolvimento.
Outra maneira de evitar reuniões para que você possa realizar o trabalho é aparecer antes de qualquer outra pessoa. Pessoalmente, gostamos de aparecer cedo porque, em geral, o escritório é mais silencioso. A maioria das pessoas que aparece cedo é como você, apenas querendo fazer o trabalho para que ninguém o incomode.
Isso é importante para colaboradores individuais, porque nosso trabalho exige momentos em que nos concentramos e não conversamos com outras pessoas. Sim, há momentos em que você pode resolver problemas em que pode querer trabalhar com outras pessoas. Mas assim que você passar pelos problemas de bloqueio, precisará codificar. É sobre entrar nessa zona em que você está constantemente segurando muitas idéias complexas sobre o trabalho que está fazendo. Se você estiver constantemente parado, pode ser difícil continuar de onde parou.
Alguns especialistas em CS começaram a usar o Git no dia em que nasceram. Eles entendem todos os comandos e parâmetros e podem fazer círculos em torno dos profissionais.
Outros experimentam o Git pela primeira vez no primeiro emprego. Para eles, o Git é um cenário infernal de comandos e processos confusos. Eles nunca têm 100% de certeza do que estão fazendo (há uma razão pela qual as folhas de dicas são populares).
Não importa qual sistema de repositório sua empresa use, o sistema será útil se você o usar corretamente e um obstáculo se for usado incorretamente. Não é preciso muito esforço para se transformar em você gastando horas tentando desembaraçar alguma mistura de vários galhos e garfos. Além disso, se você esquecer constantemente de obter a versão mais recente do repositório, também estará lidando com conflitos de mesclagem que nunca são divertidos.
Se você precisar manter uma folha de dicas de comando Git, faça-o. O que quer que torne sua vida mais simples.
Uma tendência que os engenheiros mais jovens podem ter é tentar implementar tudo o que sabem em uma solução. Existe esse desejo de entender sua programação orientada a objetos, estruturas de dados, padrões de design e novas tecnologias e usar tudo isso em cada pedaço de código que você escreve. Você cria uma complexidade desnecessária porque é muito fácil anexar-se excessivamente a uma solução ou padrão de design que você usou no passado.
Há um equilíbrio com conceitos de design complexos e código simples. Padrões de design e design orientado a objetos devem simplificar o código no grande esquema das coisas. No entanto, quanto mais um processo é abstraído, encapsulado e com caixa preta, mais difícil pode ser a depuração.
Isso vale para qualquer função, seja você um analista financeiro ou um engenheiro de software. Mas, em particular, os papéis da tecnologia parecem ter todos precisando de algo deles. Se você é um engenheiro de dados, provavelmente será solicitado a fazer mais do que apenas desenvolver pipelines. Algumas equipes precisarão de extrações de dados, outras precisarão de painéis e outras precisarão de novos pipelines para seus cientistas de dados.
Agora, priorizar e dizer não podem realmente ser duas habilidades diferentes, mas elas estão intimamente ligadas. Priorizar significa que você gasta apenas um tempo de alto impacto para a empresa. Considerando que dizer não às vezes significa apenas evitar o trabalho que deve ser tratado por uma equipe diferente. Eles geralmente acontecem em conjunto para todas as funções.
Essa pode ser uma habilidade difícil de adquirir, pois é tentador aceitar todos os pedidos apresentados em seu caminho. Especialmente se você for direto para a faculdade. Você quer evitar decepcionar alguém e sempre recebeu uma quantidade considerável de trabalho.
Nas grandes empresas, há sempre uma quantidade infinita de trabalho. A chave é apenas assumir o que pode ser feito.
Existem muitas habilidades que não são testadas em entrevistas ou mesmo sempre ensinadas em faculdades. Muitas vezes, isso é mais uma limitação do ambiente do que uma falta de desejo de expor os alunos a problemas que existem em ambientes reais de desenvolvimento.
Uma habilidade que é difícil de testar em uma entrevista e difícil de replicar quando você está fazendo cursos na faculdade é pensar em como um usuário final pode usar seu software incorretamente. Costumamos fazer referência a isso como pensar em cenários operacionais.
No entanto, essa é apenas uma maneira educada de dizer que você está tentando falsificar código de prova.
Por exemplo, como grande parte da programação é de manutenção, muitas vezes significa alterar código altamente confuso com outro código. Mesmo uma alteração simples requer o rastreamento de todas as referências possíveis de um objeto, método e / ou API. Caso contrário, pode ser fácil quebrar acidentalmente os módulos que você não percebe que estão conectados. Mesmo se você estiver apenas alterando um tipo de dados em um banco de dados.
Também inclui pensar em casos extremos e pensar em todo um projeto de alto nível antes de iniciar o desenvolvimento.
Quanto aos casos mais complexos em que você está desenvolvendo novos módulos ou microsserviços, é importante dedicar seu tempo e refletir sobre os cenários operacionais do que você está construindo. Pense em como os usuários futuros podem precisar usar seu novo módulo, como eles podem usá-lo incorretamente, quais parâmetros podem ser necessários e se existem maneiras diferentes de um futuro programador precisar do seu código.
Simplesmente codificar e programar é apenas parte do problema. É fácil criar software que funcione bem no seu computador. Mas há várias maneiras de implantar código pode dar errado. Uma vez em produção, é difícil dizer como o código será usado e que outro código será anexado ao seu código original. Daqui a cinco anos, um futuro programador pode ficar frustrado com as limitações do seu código.

ALGORITMO DO YOUTUBE CONDUZ A CONTEÚDOS CADA VEZ MAIS EXTREMISTAS, SOBRETUDO À DIREITA NO ESPECTRO POLÍTICO
Alguns algoritmos de inteligência artificial (IA) são desenvolvidos para aprender a reconhecer a música preferida do usuário, o gênero de filmes que lhe interessa, os assuntos que busca no jornal. O objetivo desse tipo de programação é identificar padrões – e, assim, automatizar decisões e facilitar a vida das pessoas. No entanto, por serem feitos para assimilar modelos de comportamento, os algoritmos também podem replicar atitudes que reforçam o racismo, a misoginia e a homofobia. Absorvem, reproduzem e, como resultado, robustecem a discriminação e a intolerância nas mais variadas formas.
Em agosto deste ano, um estudo realizado por pesquisadores da Universidade Federal de Minas Gerais (UFMG) apresentou um exemplo tão contundente desse círculo vicioso que repercutiu em diversas publicações da imprensa internacional: um processo de radicalização política no YouTube no contexto norte-americano, onde o algoritmo de recomendação tem um importante papel. “Já havia pesquisas qualitativas e reportagens que mostravam o YouTube como um terreno fértil para a proliferação de comunidades obscuras vinculadas à chamada alt-right [direita alternativa] norte-americana, cujas ideias são intimamente relacionadas à supremacia branca”, diz o cientista da computação Manoel Horta Ribeiro, atualmente doutorando na Escola Politécnica Federal de Lausanne (EPFL), na Suíça. No mestrado na UFMG, sob orientação dos cientistas da computação Wagner Meira Jr. e Virgílio Almeida, ele queria entender como esse fenômeno acontecia.
O grupo vasculhou 331.849 vídeos de 360 canais de diferentes orientações políticas e rastreou 79 milhões de comentários. Um volume imenso de dados, tratável justamente graças a recursos de inteligência artificial. “O único trabalho manual foi a classificação dos canais conforme a orientação política, utilizando estudos e dados de ONGs [Organizações Não Governamentais] como a ADL [Anti-Defamation League]”, diz Ribeiro. Os resultados revelaram que os canais supremacistas brancos são beneficiados pela migração de apreciadores de canais politicamente conservadores de conteúdo menos radical. “Rastreamos a trajetória dos usuários que comentavam vídeos de canais conservadores e descobrimos que, com o passar do tempo, eles comentavam vídeos dos canais mais radicais. Havia uma migração consistente dos conteúdos mais leves para os mais extremos”, lembra Ribeiro. “Ainda estamos tentando entender o porquê dessa migração, mas acho que três razões podem explicar o fenômeno: o formato da mídia, na qual todos podem criar conteúdo e na qual os espectadores interagem muito diretamente com os criadores; o atual cenário político mundial; e o algoritmo, que permite que usuários encontrem ou continuem a consumir conteúdo extremista por meio do sistema de recomendação.”
As pesquisas envolvendo o YouTube vêm se tornando mais relevantes nos últimos anos. Segundo o cientista da computação Virgílio Almeida, professor emérito do Departamento de Ciência da Computação da UFMG, a plataforma de vídeos já se mostrou muito interessante para a ciência. “O número de usuários é enorme – mais de 2 bilhões no mundo e 70 milhões no Brasil –, assim como seu impacto na sociedade”, diz o pesquisador. Seu departamento se tornou um verdadeiro celeiro de pesquisas sobre o fenômeno das redes sociais.
Com experiência anterior em análise de desempenho de sistemas computacionais, Almeida começou a se dedicar às redes sociais em 2007. Em uma sociedade cada vez mais conectada, o número e a abrangência dos estudos nesse campo cresceu. “Além dos alunos de computação, tive estudantes de economia, psicologia e letras. Entre os colaboradores mais recentes alguns são do direito, da administração e das ciências políticas”, enumera Almeida.
Os estudos que tiveram maior repercussão vieram do campo político – polarizado tanto nos Estados Unidos quanto no Brasil. Em 2018, uma análise de discurso de ódio e discriminação em vídeos postados no YouTube por grupos de direita norte-americanos teve destaque na International ACM Conference on Web Science, na Holanda. O trabalho foi reconhecido como o melhor feito por estudantes: os alunos de doutorado Raphael Ottoni, Evandro Cunha, Gabriel Magno e Pedro Bernardina – todos do grupo de Wagner Meira Jr. e Virgílio Almeida.
Para investigar as falas transcritas dos YouTubers e os comentários postados nos vídeos, os pesquisadores da UFMG utilizaram as ferramentas Linguistic Inquiry Word Count (LIWC) e Latent Dirichlet Allocation (LDA). O LIWC permite a classificação de palavras em categorias correspondentes à estrutura das frases (pronomes, verbos, advérbios etc.) e ao conteúdo emocional (se expressam alegria, tristeza, raiva etc.). O LDA busca palavras que possam definir os principais tópicos de uma conversa.
“Utilizamos também uma ferramenta baseada em um teste psicológico para observar o viés dessas postagens”, explica Raphael Ottoni. Segundo ele, a ferramenta se baseia na comparação das distâncias entre palavras situadas em um mesmo contexto, com o fim de estabelecer associações. Isso é feito por meio de técnicas de aprendizado de máquina que convertem as palavras de um texto em vetores de números, por sua vez usados para calcular a similaridade semântica das palavras. Assim, em um determinado assunto, palavras que se situam mais próximas tendem a estabelecer entre si uma associação de significado. “Palavras como cristianismo apareciam no texto associadas com atributos de valor positivo, como bom ou honesto, enquanto islamismo era frequentemente relacionada a terrorismo e morte”, diz Ottoni. Semelhante tendência preconceituosa foi encontrada nas referências a comunidades LGBTQI+.
Essas técnicas foram, então, aplicadas à conjuntura brasileira. Os pesquisadores estudaram vídeos publicados no YouTube durante o período de eleições presidenciais de 2018, em 55 canais identificados com posições políticas desde a extrema esquerda até a extrema direita. Mensagens de ódio e teorias conspiratórias foram identificadas com mais frequência nos canais de extrema direita – e foram justamente esses que tiveram maior crescimento no número de visualizações, possivelmente influenciando o resultado das urnas.
O grupo de pesquisadores está agora finalizando um artigo sobre os resultados dessa análise. Mas, antes mesmo da publicação, o estudo foi citado por uma reportagem do jornal The New York Times, que fez uma série sobre a influência do YouTube em diferentes países, com destaque para o Brasil.

MECANISMOS DE BUSCA E REDES SOCIAIS REFLETEM E REFORÇAM PRECONCEITOS
Segundo Almeida, outras pesquisas já constataram que os algoritmos de recomendação de notícias e vídeos acabam se valendo da atração humana por notícias negativas e teorias conspiratórias para aumentar o engajamento dos usuários com a plataforma. “Uma pesquisa de um grupo do MIT [Instituto de Tecnologia de Massachusetts] publicada na revista científica Science mostra que os medos, as raivas as emoções mais extremas são fatores-chave na disseminação de tweets com falsidades”, destaca.
Da mesma maneira que o algoritmo aprende as músicas e os filmes preferidos do usuário, ele também aprende suas preferências políticas, razão pela qual as plataformas de compartilhamento de conteúdo – como o Facebook – transformam-se em bolhas quase intransponíveis de um determinado espectro político. O usuário recebe apenas as informações que corroboram suas opiniões prévias.
Foi para estudar esse fenômeno – inspirado pelo livro O filtro invisível (Zahar, 2012), do ativista político norte-americano Eli Pariser – que o cientista da computação norte-americano Christo Wilson, da Northeastern University, dos Estados Unidos, entrou no campo das redes sociais, em 2012. “Minhas pesquisas focavam, originalmente, o estudo da personalização dos algoritmos utilizados pelos mecanismos de busca, e desde então tenho expandido para outros tipos de algoritmos e contextos”, disse o pesquisador para Pesquisa FAPESP.
Atualmente em período sabático no Centro Berkman Klein para Internet e Sociedade, da Universidade Harvard, Estados Unidos, onde Almeida atua como professor-associado, Wilson tem acompanhado com interesse os achados dos pesquisadores mineiros. “Gosto muito dos estudos de Virgílio Almeida, Wagner Meira e Fabrício Benevenuto; eles fazem um trabalho incrível nas mídias sociais.” Em 2020, Wilson também pretende se voltar ao campo da política: planeja um grande estudo acerca do impacto das redes sociais nas próximas eleições de seu país. “Vamos monitorar a maioria dos serviços on-line para tentar entender como as pessoas encontram conteúdos e como eles afetam seu comportamento”, adianta.

EM MEIO A UMA PROFUSÃO DE VÍDEOS, É DIFÍCIL FUGIR DE UMA VISÃO PARCIAL
A política é apenas um dos muitos temas que têm estimulado pesquisas do Departamento de Ciência da Computação da UFMG. O viés algorítmico pode ser encontrado onde menos se espera – como, por exemplo, nos serviços de assistentes inteligentes de voz do celular. Uma pesquisa realizada em parceria entre a Universidade de Fortaleza (Unifor) e o grupo da UFMG identificou que a eficiência dos assistentes de voz, como Google e Siri, varia conforme o sotaque e o nível de escolaridade.
A cientista da computação Elizabeth Sucupira Furtado, coordenadora do Laboratório de Estudos dos Usuários e da Qualidade em Uso de Sistemas (Luqs) conduziu um estudo qualitativo, em sessões individuais e presenciais, com dois grupos de voluntários: moradores da capital cearense, entre os quais vários nascidos em outros estados, e estudantes de uma classe noturna de Educação de Jovens e Adultos (EJA). “Percebemos que os usuários nascidos nas regiões Sudeste e Sul eram mais compreendidos pelos softwares de assistentes de voz do que os outros”, revela a pesquisadora.
Erros de pronúncia (cacoépia), gagueira ou repetição de palavras e truncamentos (disfluência) também trouxeram prejuízos ao desempenho dos assistentes robóticos. Segundo a pesquisadora, uma vez que o sistema aprende com usuários que têm mais escolaridade, o treinamento dos assistentes de voz tende a se limitar a falas padronizadas. “É importante que as empresas percebam que existe um público que não está sendo atendido”, alerta Furtado. “Essas pessoas continuam excluídas da inovação tecnológica.”
Nos mecanismos de busca também se ocultam preconceitos. Foi o que demonstrou a cientista da computação Camila Souza Araújo em sua dissertação de mestrado pela UFMG, em 2017. Nos buscadores do Google e do Bing, a pesquisadora procurou pelos termos “mulheres bonitas” e “mulheres feias” e constatou um preconceito indiscutível de raça e idade. As mulheres identificadas como bonitas eram, majoritariamente, brancas e jovens. O viés se reproduziu na maioria dos 28 países onde o buscador Bing está presente e 41 países que utilizam o Google, mesmo os situados no continente africano.
Ao utilizar sistemas de aprendizagem de máquina, a sociedade corre o risco de perpetuar preconceitos inadvertidamente, graças ao senso comum que vê a matemática como neutra. Um engenheiro de dados norte-americano, Fred Benenson, cunhou um termo para definir esse risco: mathwashing. Ele se baseou no greenwashing, o uso de estratégias de marketing pelas empresas para simular preocupação ambiental. Da mesma maneira, a ideia de que os algoritmos sejam neutros também beneficia e isenta de responsabilidade as empresas que os utilizam.
Ocorre que os sistemas de inteligência artificial são alimentados por dados, e quem faz a seleção desses dados são seres humanos – que podem ser movidos por preconceitos de forma inconsciente ou intencional. Um exemplo disso foi explicitado por um estudo publicado em outubro na revista Science, liderado por um pesquisador da Faculdade de Saúde Pública da Universidade da Califórnia em Berkeley, nos Estados Unidos. Em um grande hospital daquele país, o grupo norte-americano verificou que o algoritmo responsável por classificar os pacientes mais necessitados de acompanhamento – por estarem em maior risco – privilegiava brancos em detrimento de negros. Isso acontecia porque o sistema se baseava nos pagamentos aos planos de saúde, que são maiores no caso de pessoas que têm mais acesso a atendimento médico, e não na probabilidade de cada um ter doenças graves ou crônicas.
Em um estudo que se tornou referência na área, Solon Barocas, professor de Ética e Política em Ciência de Dados da Universidade Cornell, nos Estados Unidos, e organizador do workshop internacional “Justiça, responsabilidade e transparência na aprendizagem de máquina”, detalhe maneiras de se estabelecer o viés algorítmico
Para que a máquina inicie seu aprendizado, ela precisa saber que informações buscar. Por exemplo: se o objetivo é criar um filtro de spam, ela precisa aprender quais são os atributos ou características de uma mensagem que se deseje rotular como spam. Pòde ser o endereço de IP ou determinadas frases do conteúdo (“pílula mágica para perda de peso”, “milhões de dólares para você” etc.)
O viés ocorre quando o sistema de IA é treinado com dados tendenciosos ou infere dados a partir de amostras enviesadas. Por exemplo: o St. George’s Hospital, no Reino Unido, havia desenvolvido uma ferramenta para classificar candidatos à faculdade de medicina. Mas esse sistema se baseava em exemplos de admissões anteriores, que desfavoreciam mulheres e minorias raciais. O processo automatizado passou a refletir uma discriminação do passado.
O universo de dados pode ser parcial. Por exemplo: o aplicativo Street Bump foi desenvolvido em 2012 pela prefeitura de Boston, nos Estados Unidos, para obter dados sobre as condições das ruas. Os dados, coletados por motoristas voluntários enquando dirigem, fornecem ao governo informações em tempo real para planejar as manutenções necessárias. Como há mais usuários de automóveis e smartphones entre as pessoas mais ricas, bairros pobres ficam de fora.
Quando uma empresa simplifica demais a seleção de dados, por questão de tempo ou custo, o resultado provevelmente será discriminatório. Por exemplo: um sistema de seleção de vagas de emprego que aceite apenas candidatos formados em universidades com altas mensalidades.
Nem sempre os dados disponíveis são suficientes para traçar correlações precisas e são usadas informações substitutas. Por exemplo: moradores de uma determinada região têm maiores problemas com inadimplência e um sistema hipotético de IA usa esse dado para decidir se clientes de um banco podem receber empréstimos. Se o CEP da residência tiver relação com a origem racial, ao considerar a região de moradia o sistema discriminaria a etnia.
Proteger a sociedade da desinformação e do preconceito disseminados pela inteligência artificial é um desafio que poderia contar com a ajuda da tecnologia: a própria inteligência artificial pode oferecer formas de prevenção e controle.
Já existem, por exemplo, avanços na identificação das notícias falsas, mais conhecidas como fake news. Em outubro de 2018, um grupo de pesquisadores da Universidade de São Paulo (USP) e da Universidade Federal de São Carlos (UFSCar) lançou a versão piloto de uma ferramenta digital com esse objetivo. Ela está disponível, gratuitamente, via web ou WhatsApp. Basta submeter a notícia suspeita ao sistema de verificação. Ao constatar indícios de falsidade, o sistema responde: “Essa notícia pode ser falsa. Por favor, procure outras fontes confiáveis antes de divulgá-la”.
Segundo os autores do estudo, por enquanto o sistema consegue identificar, com precisão de até 90%, notícias que são totalmente falsas ou totalmente verdadeiras. Para separá-las, são usados parâmetros como o número de verbos, substantivos, adjetivos, advérbios, pronomes e, sobretudo, erros ortográficos presentes nos textos.
Na Universidade Estadual de Campinas (Unicamp), um grupo liderado pelo cientista da computação Anderson Rocha, diretor do Instituto de Computação, tem se dedicado a desenvolver mecanismos de identificação de informações falsas veiculadas em fotos e vídeos. “Utilizamos técnicas de IA para comparar as informações que estão em determinado texto com comentários e possíveis imagens. Ao verificarmos esses três grupos de informação, apontamos a possibilidade de discrepância que pode levar à identificação de notícia falsa”, diz Rocha.
Os pesquisadores da Unicamp também se dedicam à identificação das falsificações incrivelmente realistas de áudio e vídeo, conhecidas como deep fakes, e ao estudo da autoria de textos postados em rede social, por meio de uma técnica que avalia o estilo de escrita do autor – a estilometria. Outra frente de pesquisa do grupo é a filogenia digital: “Buscamos o processo de evolução de um determinado objeto digital – imagem, vídeo ou texto – que sofre alterações sucessivas em sua versão original”, explica Rocha. O objetivo é identificar como determinada notícia postada em rede social vai sendo modificada ao longo do tempo por diferentes pessoas que adicionam ou removem elementos. “Dificilmente teremos uma única solução, global e genérica, para o combate às fake news, mas desenvolvemos ferramentas pontuais que vão enfrentando caso a caso. Para que conseguíssemos um salto que nos permitisse disponibilizar ferramentas de controle para a sociedade, precisaríamos ter investimento do setor privado tentando trazer esse conhecimento gerado na academia e transformar em produto”, opina o pesquisador.
Do setor privado também se espera maior transparência no desenvolvimento das ferramentas tecnológicas. O termo “responsabilidade algorítmica” tem sido cada vez mais utilizado nos debates sobre o uso da IA. Segundo o advogado Rafael Zanatta, especialista em direito digital e pesquisador do grupo de Ética, Tecnologia e Economia Digitais da USP, ainda não existem leis específicas relacionadas aos aspectos discriminatórios de algoritmos, mas já há iniciativas nesse sentido. Nos Estados Unidos, foi apresentado um projeto de lei denominado Algorithmic Accountability Act. Se ele for aprovado, as empresas terão que avaliar se os algoritmos que alimentam os sistemas de IA são tendenciosos ou discriminatórios, bem como se representam um risco de privacidade ou segurança para os consumidores. “Essa lei segue um pouco da lógica da legislação ambiental, é uma espécie de avaliação de impacto da ferramenta tecnológica”, compara Zanatta.
Em abril deste ano, a União Europeia divulgou uma série de diretrizes éticas para o uso da inteligência artificial. Entre elas, o estabelecimento de medidas que responsabilizem as empresas pelas consequências sociais da utilização da IA e a possibilidade de intervenção e supervisão humanas no funcionamento do sistema.
No Brasil, também se tentou introduzir uma lei prevendo a revisão humana de decisões automatizadas. Um cidadão que se sentisse prejudicado por uma decisão mediada por algoritmos – na concessão de um empréstimo, por exemplo – poderia requerer um revisor para esclarecer os critérios utilizados para a decisão. No entanto, o projeto foi vetado em julho de 2019 pela Presidência da República, sensível ao argumento das empresas de que a revisão humana acarretaria custos adicionais.

PESQUISAS SOBRE MULHERES BONITAS REVELAM UMA VISÃO RACISTA
Para Virgílio Almeida, a proteção contra o uso tendencioso da IA começa na educação. Ele destaca como exemplo a iniciativa de escolas da Finlândia que estimulam as crianças a desenvolverem espírito crítico e identificarem notícias falsas na web. Não basta, claro, educar o usuário, é preciso educar também o programador. “Para evitar o viés, uma das maneiras é dispor de dados mais diversos para treinar o algoritmo”, lembra o professor.
A estudante de graduação Bruna Thalenberg, uma das fundadoras do Tecs – Grupo de Comput{ação Social}, do Instituto de Matemática e Estatística (IME) da USP, concorda: “O mundo está em constante mudança, os algoritmos não deveriam repetir o passado”. Fundado em 2017 como uma equipe de extensão, o Tecs nasceu do diálogo de estudantes da USP com o colega brasileiro Lawrence Muratta, que fazia ciência da computação na Universidade Stanford, nos Estados Unidos, onde já havia um grupo discutindo a questão do viés.
“Sentíamos que o curso de ciência da computação estava muito afastado da sociedade”, conta o ex-aluno Luiz Fernando Galati, que hoje trabalha no Centro de Ensino e Pesquisa em Inovação da Fundação Getulio Vargas. Ele conta que o objetivo inicial do grupo era promover palestras e debates, mas eles acabaram propondo a inclusão de um novo curso na grade curricular, o que foi feito. “As palestras que promovemos são oferecidas hoje na disciplina direito e software, sob a supervisão dos professores Daniel Macedo Batista e Fabio Kon.” O Tecs também participa da TechShift Alliance, que reúne 20 organizações de alunos universitários das Américas do Norte, do Sul e da Ásia, dispostos a debater as questões sociais ligadas à inteligência artificial. Os grupos se reúnem em um evento anual, chamado TechShift Summit.
Como seu próprio nome indica, além da reflexão, o grupo tem o propósito de se dedicar à ação, por meio de projetos que permitam a grupos marginalizados o acesso ao universo digital. Um desses projetos é o ensino de lógica de programação para alunos do Centro de Atendimento Socioeducativo ao Adolescente, a Fundação Casa. “O projeto surgiu de um contato entre uma integrante do Tecs e o Projeto Primeiro Livro, que fazia ações em unidades da Fundação Casa e em escolas públicas. A primeira turma do curso iniciou no segundo semestre de 2018”, conta a estudante Jeniffer Martins da Silva, educadora do projeto. Desde sua criação, mais de 40 jovens já passaram pelo curso.
Para os integrantes do Tecs, não são apenas os grupos atendidos pelo projeto que podem se beneficiar com os cursos, mas a área da ciência da computação como um todo. “Qualquer equipe com mais diversidade tem melhor desempenho. Mais riqueza de perspectivas leva a melhores e mais inovadoras soluções para os desafios que precisarem superar”, conclui Silva.
Publicado por: NEXO Jornal
 Trabalhar na Google é um sonho de vários engenheiros/futuros engenheiros, com destaque para os engenheiros de software. A Google possui a fama de ter ótimos escritórios (há dois no Brasil, um em Belo Horizonte e outro em São Paulo) e os salários são absurdamente motivadores, fatores que justificam a concorrência altíssima . Se você é um engenheiro/futuro engenheiro de software, então precisa conferir essas dicas que a empresa divulgou sobre como se tornar um bom engenheiro de software.
Trabalhar na Google é um sonho de vários engenheiros/futuros engenheiros, com destaque para os engenheiros de software. A Google possui a fama de ter ótimos escritórios (há dois no Brasil, um em Belo Horizonte e outro em São Paulo) e os salários são absurdamente motivadores, fatores que justificam a concorrência altíssima . Se você é um engenheiro/futuro engenheiro de software, então precisa conferir essas dicas que a empresa divulgou sobre como se tornar um bom engenheiro de software.
Eles fornecem instruções básicas sobre programação.
Recomendações: Udacity – intro to CS course, Coursera – Computer Science 101
Recomendações (nível iniciante): Coursera – Learn to Program: The Fundamentals, MIT Intro to Programming in Java, Google’s Python Class, Coursera – Introduction to Python, Python Open Source E-Book
Recomendações (nível intermediário): Udacity’s Design of Computer Programs, Coursera – Learn to Program: Crafting Quality Code, Coursera – Programming Languages, Brown University – Introduction to Programming Languages
Adicione outras linguagens de programação em seu repertório, como Java Script, CSS, HTML, Ruby, PHP, C, Perl, Shell.
Recomendações: w3school.com – HTML Tutorial, CodeAcademy.com, Udacity – Mobile Web Development, Udacity – HTML5 Game Development
Aprenda a identificar erros, crie testes e hackeie seu próprio software.
Online Resources: Udacity – Software Testing Methods, Udacity – Software Debugging
Recomendações: MIT Mathematics for Computer Science, Coursera – Introduction to Logic, Coursera – Linear and Discrete Optimization, Coursera – Probabilistic Graphical Models, Coursera – Game Theory

Recomendações: MIT Introduction to Algorithms, Coursera Introduction to Algorithms Part 1 & Part 2, List of Algorithms, List of Data Structures, Book: The Algorithm Design Manual
Recomendações: UC Berkeley Computer Science 162
Recomendações: Udacity – UX Design for Mobile Developers
Recomendações: Stanford University – Introduction to Robotics, Natural Language Processing, Machine Learning
Recomendações: Coursera – Compilers
Recomendações: Coursera – Cryptography, Udacity – Applied Cryptography
Recomendações: Coursera – Heterogeneous Parallel Programming

Crie e mantenha um site, faça seu próprio servidor ou construa um robô.
Recomendações: Apache List of Projects, Google Summer of Code, Google Developer Group
Irá ajudá-lo a melhorar sua capacidade de trabalhar em equipe e permite aprender com os outros.
Pratique por meio de competições ou concursos.
Recomendações: CodeJam, ACM ICPC
Ensinar os outros estudantes te ajuda a melhorar seu conhecimento no assunto.
Mas, o guia alerta: seguir todos os itens não garante um emprego na Google. As recomendações servem para introduzir ou complementar seu conhecimento. Então, você precisa se esforçar em outras tarefas para conseguir um emprego nesta gigante empresa.
Referências: Google: Guide for Technical Development
Tempo de leitura: 4 minutos
Há sete anos a NASA lançava o Rover Curiosity para o Planeta Marte, um veículo autônomo que objetivava explorar a superfície do planeta. Em outubro deste ano, foi divulgado uma foto do Rover Curiosity fazendo uma Selfie.

Fonte: NASA (2019)
Um questionamento extremamente preponderante do ponto de vista computacional é o que está por trás do Rover Curiosity. Ao pensar rapidamente podemos responder que é o Sistema Operacional que inicializa suas aplicações, ou a Inteligência Artificial que o faz selecionar a rocha correta sem a intervenção da NASA aqui na Terra.
A resposta é que princípio de tudo é o CÓDIGO, é ele que descreve como será o Sistema Operacional, como ocorrerá a interação deste com o hardware e a aplicação e, no exemplo do Rover Curiosity, como será a interação do Sistema Operacional com o hardware do veículo e a Inteligência Artificial.
Margaret Hamilton
Margaret Hamilton é considerada a primeira Engenheira de Software, com o código do programa de voo da Apollo 11, a primeira missão tripulada à Lua de 1969, desenvolvido em Assembly com 64.992 linhas de código.
É importante destacar que, naquela época, as premissas das metodologias tradicionais de desenvolvimento foram seguidas, como teste de software, revisão e aprovação.
Todo o código da Apollo 11 pode ser encontrado no GitHub no endereço: https://github.com/chrislgarry/Apollo-11
Um outro exemplo de software amplamente utilizado, e que aqui é abordado para entender a evolução da complexidade de um código, é o Kernel do Linux. Presente em todos os celulares Android e Sistemas Operacionais Linux, como Ubuntu e Red Hat, atualmente possui mais de 20 milhões de linhas de código.
Todos os aspectos mostrados até agora foram para entender o quão complexo encontra-se o nível de codificação de sistemas. Em 1969, tínhamos um software de programa de voo com quase 70 mil linhas de código e hoje temos um sistema rodando em um celular com mais de 20 milhões de linhas de código.
Esta complexidade de sistemas norteou exigências do mercado e adaptabilidade dos Engenheiros de Software, principalmente no entendimento do Processo de desenvolvimento de Sistemas, cerne de um Projeto de Software. Quando Barry Boehm publicou, em um de seus artigos de 1988, o “Modelo Espiral”, foi uma grande mudança de paradigma em relação ao Modelo Cascata. O desenvolvimento de software passou a ter um ciclo, e a cada novo ciclo um incremento de entrega.
Em 2001, houve o advento do Manifesto Ágil através de uma nova abordagem de Metodologias, na qual o grande foco no ciclo de desenvolvimento seria o cliente e o atendimento de suas demandas, mesmo que estas ocorressem ao longo do ciclo de codificação. O cliente tornou-se, portanto, participante ativo deste processo. Desta forma, Metodologias Ágeis como Scrum, XP e FDD tornaram-se amplamente utilizadas por engenheiros de softwares em seus projetos, agregando celeridade e continuidade nas entregas e satisfação do cliente.
O conhecimento da linguagem de codificação, o entendimento da metodologia de desenvolvimento e das tecnologias envolvidas neste processo tornaram-se uma prerrogativa básica para o Engenheiro de Software, considerando os diversos nichos no qual sistemas são empregados.
Engenheirizar Software é ter uma visão macro do negócio, entender como o sistema pode melhorar aquela situação, definir melhorias de fluxos de processos no mundo real (antes de defini-los em sistemas), envolver todos os Stackeholders de maneira motivadora e participativa no projeto e, acima de tudo, criar uma nova perspectiva sistêmica que gere uma lucratividade para os envolvidos.


É possível usar sites especializados em medição do ping
Para quem joga online, ou é um heavy user de computadores, o termo ping, com certeza, soa familiar. O Packet Internet Network Grouper foi criado por Michael Muuss e é uma ferramenta usada para examinar o estado da rede local e de outros equipamentos conectados a ela. Saiba mais sobre o que é ping e como ele pode afetar em sua performance nos jogos online!
O ping é um comando que mede quanto tempo um pacote de informações leva para ir a um destino e voltar, em milissegundos (ms). Ou seja, ele verifica a velocidade de uma conexão e, quanto menor seu valor, mais rápida é a internet.
O nome ping, na verdade, é uma analogia ao som de um sonar, assim como seu modo de agir. O ping é um importante comando para determinar a qualidade da transmissão de dados online de redes e sistemas operacionais em todo o mundo.
Qualquer usuário pode usar o ping para verificar a velocidade de sua conexão, independentemente de seu sistema operacional. O primeiro passo é o seguinte:
-Windows: abra o menu iniciar e digite “cmd” ou “prompt de comando” no campo de busca;
-OS X: acesse a pasta aplicativos, depois utilitários e abra o terminal;
-Linux: acesse o terminal pelo atalho Ctrl + Alt + T.
Em seguida, basta digitar ping e inserir a URL de um site ou o IP de uma máquina que esteja conectada à sua rede e na qual a conexão será testada. Serão apresentados vários dados, como o número de pacotes e se houve perdas de dados. Ao fim, aparecem as velocidades mínima, máxima e média, em milissegundos.
Também é possível usar sites especializados em medição do ping e que eliminam a necessidade de acesso ao terminal ou ao prompt de comando, como o Teste seu Ping ou o Teste sua Velocidade.
O ideal é que o valor do ping esteja abaixo de 100 ms para que o usuário consiga jogar online. Também é importante notar se há perda de pacotes, pois caso haja, o usuário terá dificuldades para jogar, assistir vídeos etc. Caso os resultados de sua conexão não estejam dentro do esperado, o usuário pode adotar algumas medidas para minimizar o problema, como:
– usar cabos: as conexões cabeadas dão mais estabilidade e velocidade na transmissão de dados, ao contrário das conexões por Wi-fi;
– usar uma aplicação por vez: se você quer jogar seu jogo online, evite deixar o Torrent aberto, por exemplo, pois são aplicações que usam uma alta taxa de dados. Usadas ao mesmo tempo, elas causam interferências e podem atrapalhar o andamento da partida;
-evite horários de pico: horários em que muitos usuários estão conectados à rede simultaneamente podem reduzir a qualidade da conexão da internet.
-resete o modem e o roteador: às vezes é uma solução para reduzir o valor do ping. Basta desligar os aparelhos da tomada, esperar alguns segundos e religá-los;
-reclame com a operadora: por fim, vale notificar a operadora sobre os problemas com sua conexão. Em alguns casos a causa pode ser uma dificuldade da empresa ou necessidade de mudança na rota da transmissão de dados, por exemplo.
Fonte: PlayerID

Especialmente no começo, é preciso ser mão pra toda obra e a tecnologia não fica fora disso.
Se você é um empreendedor ou empreendedora, sabe que não existe descrição de trabalho nessa função. Você faz todas as tarefas que precisam ser feitas: desde o lançamento até tratar com investidores, o suporte ao cliente e trocar as lâmpadas do escritório.
Especialmente no começo, é preciso ser mão pra toda obra e a tecnologia não fica fora disso. Você pode contar a programação como uma das habilidades da sua caixa de ferramentas. Mesmo que você nunca seja um programador em tempo integral, há muito valor em saber codificar.
A maioria das empresas acaba falhando não porque fica sem dinheiro, mas porque fica sem recursos. Especialmente no mundo da tecnologia, o principal diferencial entre empresas de tecnologia bem-sucedidas e malsucedidas é seu conhecimento em tecnologia. Por essa razão, empreendedores e donos de empresas devem ter algum conhecimento de programação.
Saber disso é metade da batalha, aprender a codificar é o restante. Aqui estão algumas razões pelas quais você deve aprender a codificar.
Contratar um desenvolvedor para um único propósito é caro. Um empreendedor que possui habilidades de codificação reduz as despesas gerais imediatamente. Embora ter um desenvolvedor interno na equipe seja fundamental durante violações de segurança e falhas de servidor, essas são todas questões que um empreendedor pode aprender a lidar e até reduz custos de contratação por entender melhor qual o trabalho que deve ser feito.
Esperar que os estágios de desenvolvimento de código sejam concluídos para produto, aplicativo, software e produtos relacionados à tecnologia pode colocar em risco os cronogramas de conclusão do protótipo. Quando um empreendedor aprende a codificar, pode mover o desenvolvimento de produtos e serviços um pouco mais rápido. Isso também permite que as fases de teste do projeto ocorram mais rapidamente. Assim como torna possível a tomada de decisão sobre estratégia de produto: quais linguagens usar, como montar um time quando for a hora, quais metodologias usar no desenvolvimento, entre outras questões estratégicas.
Quando você sabe quanto tempo leva cada parte do desenvolvimento do produto, incluindo o tempo alocado para a codificação, os cronogramas do projeto são mais realistas. Isso poupa muito estresse e tensão muitas vezes sentidos pelas equipes de desenvolvimento com supervisores que não entendem o processo. Ao fornecer ao desenvolvedor um prazo apropriado, as extensões, os erros e os programas incompletos são problemas menores.
Se a aventura de empreendedorismo que você planejou não funcionar ou falhar completamente, aprender a codificar lhe dará opções de carreira para recorrer. Algumas das opções de carreira a considerar são o desenvolvimento web back-end, front-end, técnico de suporte e analista de dados, por exemplo. Empreendedores sempre precisam ter um “plano B” para o caso do caminho que você tomar acabar sendo uma estrada sem saída.
Todos os empreendedores precisam ter pelo menos um gênio técnico por trás deles para ajudar a conduzir análises de produtos, construir uma equipe de desenvolvimento e realizar testes beta. Verificar estatísticas e resultados de testes com um conjunto de olhos diferente é ideal na maioria das situações. Com duas pessoas trabalhando nos dados, os resultados chegam mais rapidamente e os planos para desenvolvimento, marketing e lançamento de produtos podem começar a funcionar.
Aprender a codificar lhe dá um conhecimento valioso para passar para os membros da sua força de trabalho. Se você é um empreendedor de desenvolvimento de aplicativos, ensinar um método específico a um membro da equipe capacita-o a ajudar em mais fases de desenvolvimento. Você tem tempo para ensinar o membro da equipe, pois os aplicativos podem levar meses para serem desenvolvidos.
Transferir o que você, como founder, aprendeu na aula de codificação para aqueles que trabalham para você constrói uma equipe mais forte, um produto final mais completo e uma equipe intercambiável para dividir as tarefas. A transferência de aprendizado é uma parte vital de ser um empreendedor de sucesso, já que muitos o encararão diretamente como mentor.
Às vezes é difícil transmitir exatamente o que você quer de um projeto. Pode ser difícil usar uma terminologia simples para explicar a uma desenvolvedora de codificação o que você imagina em sua própria mente. A capacidade de personalizar aplicativos, sites e programas garante que você esteja criando exatamente o que deseja. Além de você ser mais valioso para si mesmo por ter essas habilidades, você é mais valioso para toda a equipe.
As habilidades de auto-personalização podem levar um empreendedor de tecnologia a desenvolver novos aplicativos para ajudar os outros a aprenderem novos processos, uma nova habilidade ou resolver problemas. A mente de um empreendedor está sempre pensando na melhor maneira de fazer algo, desenvolver mais itens relacionados à tecnologia é uma demonstração disso.
Empreendedores, especialmente em novos empreendimentos de tecnologia, deveriam ser mais auto-suficientes. Os custos de operação e desenvolvimento serão menores e uma boa base de educação pode ser obtida. Um empreendedor bem-sucedido que entende todas as fases de seu negócio está se preparando para o sucesso.
Fonte: Bossabox
Você já ouviu falar em SQL? Essas três letrinhas são muito frequentes em vagas de emprego, e seus conhecimentos têm sido cada vez mais requisitados no mercado. Neste artigo vamos explicar o que é o SQL, para que serve e por que você deveria se preocupar em aprendê-lo o quanto antes.
SQL significa “Structured Query Language”, ou “Linguagem de Consulta Estruturada”, em português. Resumidamente, é uma linguagem de programação para lidar com banco de dados relacional (baseado em tabelas). Foi criado para que vários desenvolvedores pudessem acessar e modificar dados de uma empresa simultaneamente, de maneira descomplicada e unificada.
A programação SQL pode ser usada para analisar ou executar tarefas em tabelas, principalmente através dos seguintes comandos: inserir (‘insert’), pesquisar (‘search’), atualizar (‘update’) e excluir (‘delete’). Porém, isso não significa que o SQL não possa fazer coisas mais avançadas, como escrever queries (comandos de consulta) com múltiplas informações.
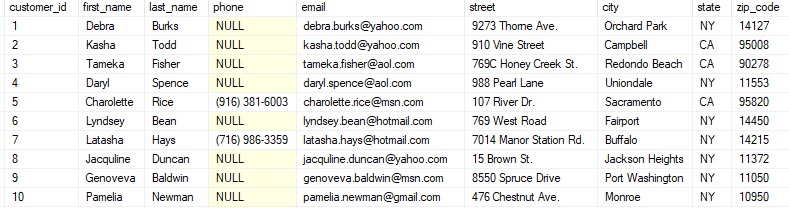
Segundo a Dataquest, escola referência em ciência de dados, existem três motivos primordiais pelo qual profissionais que usem dados precisam se preocupar em aprender a linguagem SQL:
É uma linguagem fundamental para qualquer profissional de análise, ciência ou engenharia de dados, sendo ainda mais usada do que Python e R. Contudo, devido a sua simplicidade, não é necessário ser um programador para aprendê-la, e em cada vez mais áreas têm sido exigido o conhecimento em SQL como complementar em tarefas cotidianas.
E, basicamente, qualquer área que lide com tecnologia, e tenha seus próprio banco de dados, poderá exigir conhecimento em SQL como complemento profissional.
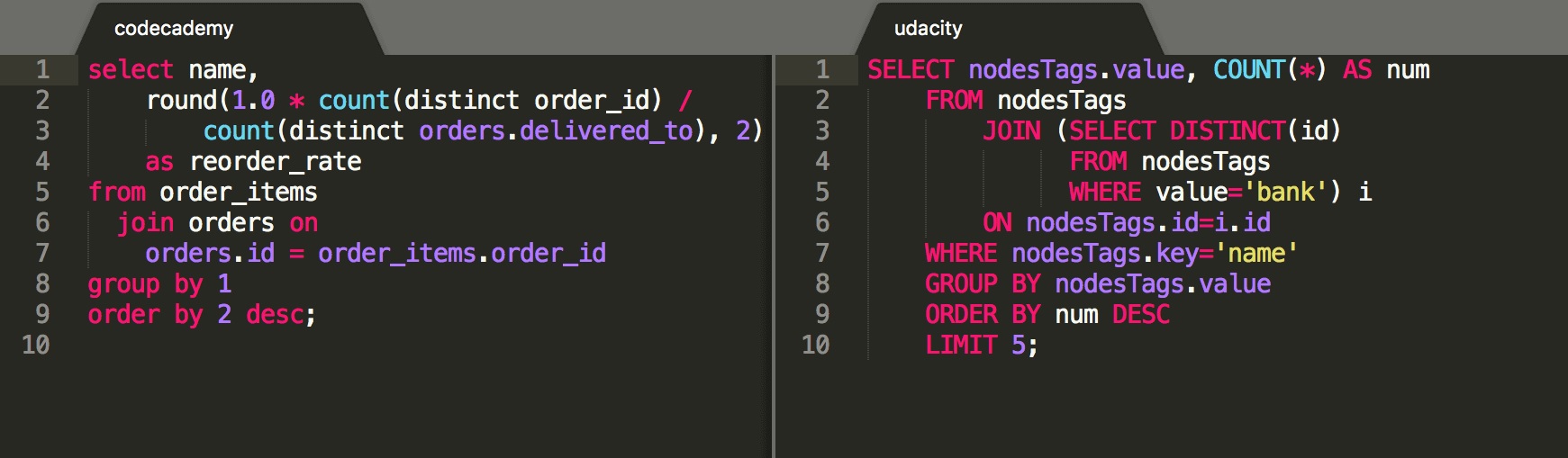
Segundo o Guia de Profissões e Salários da Catho, a média salarial de um analista de sistemas SQL no Brasil é de R$ 3.473,19; já gerentes, coordenadores e consultores de bancos de dados podem ter salários acima de R$ 7 mil.
Com o mundo digitalizado de hoje, saber lidar com grandes quantidades de dados é fundamental. A linguagem SQL já é tida como um dos conhecimentos pilares de qualquer profissional que atua com tecnologia; além disso, com a alta competitividade do mercado, saber uma informação tão útil quanto o SQL com certeza é um ótimo diferencial.
he impacts of new technologies are unpredictable: Inventors hyperbolize a revolutionary technology when it emerges, but it’s impossible for society to anticipate its long-term effects. Because new technologies are so powerful and incomprehensible, responsible technologists must practice what the poet John Keats called negative capability: “capable of being in uncertainties, Mysteries, doubts, without any irritable reaching after fact,” simultaneously cultivating caution and enthusiasm.
I’ve been thinking about technology enthusiasm as long as WIRED has been published. Long an editor of competing magazines, I now help build life sciences companies, mostly in health and agriculture. Witness and participant, I’ve become (to my slight surprise) a person of a fixed, familiar ideology, one of those blithe bastards who think technology can solve big problems, grow wealth, and enlarge human possibilities. All I lack is the fleece vest.
I’m not an absolute fool about technology: a determinist or militant naif. I know that most technologies are contingent, neither necessary nor impossible, and that use makes a particular technology good or bad, according to circumstance and effect. I don’t forget Clay Shirky’s rueful dictum that “it’s not a revolution if nobody loses,” and I concede that the losers in any technologically wrought social transformation are often those with the least to lose. But I believe that any broadly adopted technology satisfies some profound human need. We are technology-making apes who evolve through our material culture; everywhere, people fly like birds, speed like cheetahs, and live as long as lobsters, but only because of our technologies. I’m confident that smart, generous policies can ameliorate technological unemployment and other displacements.

More religiously, while I recognize that technological solutions create new problems, I have faith those problems will find yet more solutions, in an ascending spiral of frustration and release—the greatest show on Earth that will never end, until we do.
Science, unlike technology, is an absolute good, and learning about the world is a kind of categorical imperative: an unconditional moral obligation that is its own justification. Those who expand human thought are especially heroic, because they replace obscurity with the truth, which however so shocking is always salutary.
But science is only directly useful insofar as it leads to new technologies. In my new life, I often ask myself: With the time I have left, what novel technologies should I pursue? Which should I reject? Not long ago, the partners at my firm considered a technology that might prevent disease. But we chose to let someone else commercialize it, because its expansive powers and potential liability confounded us. Was our choice admirable or cowardly?
These are not easy questions, not least because there is no consensus—and surprisingly little systematic writing—about what technology is and how it develops. The best general book on the subject, Brian Arthur’s The Nature of Technology: What It Is and How It Evolves (2009) distinguishes between the singular use of the word technology as a means to fulfill a human purpose (for instance, a speech-recognition algorithm or filtration process) and a generic assemblage of practices and components (technological “domains,” like electronics or biotechnology). Arthur, an economist at the Santa Fe Institute who refined models of increasing returns, writes, “A technology is more than a mere means. It is … an orchestration of phenomena to our use.”
If technology is functional and its value instrumental, then it follows that not all singular applications of technological domains are equal. Nuclear fission can power a plant or detonate a bomb. The Haber-Bosch process, which converts atmospheric nitrogen to ammonia by a reaction with hydrogen, was used to manufacture munitions in Germany during World War I, but half the world’s population now depends on food grown with nitrogen fertilizers. (Fritz Haber, who was awarded the 1918 Nobel Prize in Chemistry for coinventing the process, was a conflicted technologist—the father of chemical warfare in World War I. His wife, also a chemist, killed herself in protest, in 1915.) What’s more, designs possess a moral direction, even if technologies can be put to different uses. You can hammer a nail with a pistol butt, although that’s not what it’s for; a spade can kill a man, but it’s better for digging. Therefore, the first commandment for technologists is: Design technologies to swell happiness. A corollary: Do not create technologies that might increase suffering and oppression, unless you’re very sure the technology will be properly regulated.
However, the regulation of new technologies presents a special problem. The future is unknowable, and any really revolutionary technology transforms what it means to be human and may threaten our survival or the survival of the species with whom we share the planet. Haber’s fertilizers fed the world’s people, but also fed algae in the sea: Fertilizer runoffs have created algae blooms, which poison fish. The problem of unpredictable effects is especially acute with some energy and all geoengineering technologies; with biotechnologies such as gene drives that can force a genetic modification through an entire population in a few generations; with artificial eggs and sperm that might allow parents to augment their offspring with heritable traits.
One tool to regulate future technologies is the precautionary principle, which in its strongest form warns technologists to “first do no harm.” It’s an alluringly simple rule. But in an influential paper on the principle, the Harvard jurist Cass Sunstein cautions, “Taken in [its] strong form, the precautionary principle should be rejected … because it leads in no directions at all. The principle is literally paralyzing—forbidding inaction, stringent regulation, and everything in between.” A weaker version, adopted by the nations that attended the Earth Summit in Rio in 1992, stipulates, “Where there are threats of serious or irreversible damage, lack of full scientific certainty shall not be used as a reason for postponing cost-effective measures to prevent environmental degradation.” The threshold for plausible harm is left worryingly undefined in most weak versions of the principle. Nonetheless, the weaker version suggests a second commandment for technologists: In regulating new technologies, balance costs and benefits, and work with your fellow citizens, your nation’s lawmakers, and the world’s diplomats to enact reasonable laws that limit the potential damage of a new technology, as further evidence is forthcoming. It’s good that Facebook invented a global social network, but the company must now cooperate with regulators to limit how malefactors can hack our heads, maddening populations and hijacking elections.
A final commandment helps technologists choose which technologies to pursue. In a complicated fashion, new technologies are not only the “orchestration of phenomena to our use” but are tools of scientific inquiry. Brian Arthur notes, “Science not only uses technology, it builds itself from technology.” High-throughput screening speeds drug discovery, but it also provides new understanding of cancer genomics. Deep learning may one day permit driverless cars, but it will also untangle the mysteries of brain development. Thus, the third commandment for technologists: The best technologies have utility but also provide fresh scientific insights. Prioritize those.
On my desk at work, I have a replica of the skull of La Ferrassie 1, the most complete Neanderthal skeleton ever found. The original belonged to an adult male who lived 50,000 to 70,000 years ago. He walked as upright as you or me, and had you met him on a Paleolithic hillside in what is now the Vézère Valley in France, he would have seemed hauntingly strange: obviously human but stockier, broad-nosed, and beetle-browed. In ways we can only dimly guess, his manners would have been strange too. Surely, he could talk after a fashion, because he possessed the anatomy for speech and shared with us a gene, FOXP2, necessary for the development of language. But the archeological record tells us that he was also different from Homo sapiens. Around 70,000 years ago something switched on in the heads of modern humans—either a genetic mutation or a social adaptation; we don’t know what—that allowed us to design new stone tools that Neanderthals only clumsily imitated, as well as make cave art, flutes, wine, and, eventually, all the rest: the vault of King’s College Chapel, Cambridge; Darwin collecting his irrefutable facts; a cure for cancer; the mission to Mars.
Avenida Presidente Kennedy, 1100 - São Cristovão - 64052-335 - Teresina-PI
Telefone: (86) 9807-1976 - E-mail: contato.icev@somosicev.com
